#Nginx설치 #Nginx-install #웹서버 설정 #Nginx웹서버설치 #웹서버튜닝 #high performancen nginx #system performance tunning #웹서버 튜닝 #성능개선 #시스템튜닝 #파일시스템 튜닝
1. 디스크의 I/O 병목 줄이기
2. 프로세스 처리량 늘리기 (Process)
3. TCP 관련 처리량 늘리기
4. 메모리 및 CPU 튜닝하기 (Processor)
5. 마이크로캐싱
6. 로그 부하 줄이기
7. Dos, DDos 방어 설정

[꿀팁]고성능 Nginx를위한 튜닝(4)-메모리 및 CPU 튜닝하기 (Processor)
대량의 트레픽을 처리 하기 위해서 CPU와 메모리를 이용하여 처리량을 늘리는 것이 마지막 단계의 튜닝 단계라고 보여 집니다. 실제 성능에서 개선 효과가 미묘할 수 도 있습니다.
CPU와 메모리의 튜닝은 대량의 처리를 위한 리소스 할당과 context 처리를 위한 방식 그리고 사용중인 리소스의 빠른 반환과 재할당에 있습니다. 그런 측면에서는 Nginx Core 자체 아키텍처의 개선된 특징점을 알아 두는 것이 좋겠습니다.
Nginx에 대한 CPU는 처리량에 적절한 Core를 할당하는 것과 WorkPorcess 수를 코어에 맞게 설정 하는 것입니다. 기존 Apache나 Multi-Thread 방식의 프로그램과 달리 nginx는 이벤트 기반의 처리 기술을 도입하여 cpu와 memory를 효과적으로 사용 할 수 있습니다.
ㅁ 웹서버의 프로세스 처리 방식 차이 이해
- 전통적인 프로세스 방식 과 이벤트 기반 방식의 차이
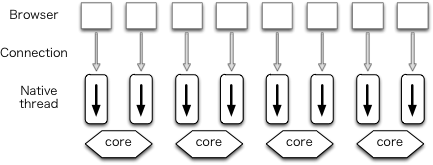
[기존 프로세스 방식 웹서버]
기존 Apache와 같은 웹서버들은 동시 연결을 처리하는데 전통적인 프로세스 방식 과 스레드 기반 모델 을 이용하여 별도의 프로세스 또는 스레드로 각 연결을 처리합니다. 그리고 네트워크 또는 입력/출력 작업을 차단하는 작업이 포함됩니다. 이때 애플리케이션에 따라 메모리 및 CPU 소비 측면에서 매우 비효율적 일 수 있습니다.
- 별도의 프로세스 또는 스레드를 생성하려면 힙 및 스택 메모리 할당과 새 실행 컨텍스트 생성을 포함하여 새로운 런타임 환경을 준비해야합니다. 이때 CPU를 소비하여 환경을만듭니다.
- 그리고 트레픽이 증가하면 과도한 컨텍스트 전환에 대한 스레드 스래싱으로 인해 성능이 저하 될 수 있습니다.
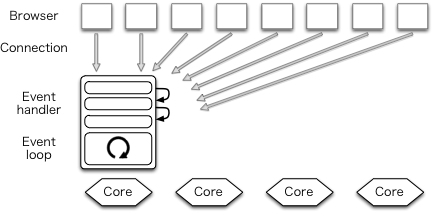
[이벤트 기반 처리 방식 웹서버]
Nginx의 아키텍처 개념은 모듈식, 이벤트 중심, 비동기, 단일 스레드, 비 차단 개념으로 구성되어 있습니다.
이벤트 중심 아키텍처를 사용하여 요청을 비동기적으로 처리합니다. 단일 스레드를 통해서 새로운 요청에 대해 새 프로세스를 생성하지 않습니다. 또 연결은 worker라고하는 제한된 수의 단일 스레드 프로세스에서 매우 효율적인 실행 루프에서 이벤트 처리됩니다 . 각 작업자 내에서 nginx는 초당 수천 개의 동시 연결 및 요청을 처리 할 수 있도록 하였습니다.
실제 웹서버는 주로 Tomcat과 같은 Web Application이나 이미지 같은 파일 데이터 전송을 담당하기 때문에 문제가 없다면 CPU를 많이 사용하지 않습니다. 만약 SSL과 같은 암호화 통신이나 gzip 통신 압축을 하는 경우 대량의 데이터 처리를 위해 평소보다 10~20% 정도 CPU를 더 사용할 정도 입니다.
ㅁ Nginx의 CPU관련 튜닝 설정
1. 워크 프로세스 수 : worker_processes
2. CPU선호도 설정 : worker_cpu_affinity
3. 프로세스당 동시 작업 연결 수 : worker_connections
[추가 설명] - worker_processes auto , upstream
1. 워크 프로세스 수 : worker_processes
워크프로세스는 유입되는 이벤트를 처리하는 프로세스로 CPU 코어수 만컴 프로세스를 기동하는 것을 권장합니다.
worker_processes 는 주로 "auto" 나 cpu core 수만큼 설정 합니다. 물론 CPU코어수 보다 많이 줄수도 있습니다.
"auto"로 설정을 하면 자동으로 알아서 설정하므로 정확한 cpu코어수에 맞추지 않아도 됩니다.
worker_rlimit_nofile 는 작업 프로세스가 최대 열수 있는 파일 수에 대한 제한을 설정하여 처리량을 늘려 줍니다.
# worker_processes number | auto;
worker_processes auto; # [auto | cpu core 수]
worker_rlimit_nofile 204800;
2. CPU선호도 설정 : worker_cpu_affinity
worker_cpu_affinity 는 CPU의 비트 마스크로 작업 프로세스를 CPU 집합에 바인딩합니다.
주로 docker 같이 하나의 시스템 내부에서 도커 별로 CPU를 고정 할당하고자 하는 경우 유용합니다. Docker와 같은 컨테이너화 된 환경에서 실행되는 경우 시스템 관리자는 호스트 시스템에서 사용 가능한 컨테이너에 더 적은 수의 코어를 할당하도록 선택할 수 있습니다.
(추가) 제대로 활용하기 위해서는 커널내부 NUMA(Non-Uniform Memory Access)와 같은 설정을 통해서 시스템 Host 자체에서 메모리와 CPU에 대한 관리도 병행 해 볼 필요는 있으나 큰 차이는 없을 듯 합니다.
(멀티코어 멀티 CPU로 MMP SMP, Numa 등 아키텍처 들이 많습니다. 이들은 시스템 메인보드 설계 부터 커널에 맞춰져 개발되는 점을 감안해야 하지만 우리가 사용하는 일반 리눅스 시스템들은 주로 SMP가 대부분입니다. )
* 다만 특정 시스템이 Host의 자원을 많이 쓰는 경우를 리소스를 제한 하는데는 NUMA도 유용할 것으로 보입니다.
# worker_cpu_affinity auto [cpumask];
worker_processes 4;
worker_cpu_affinity 0001 0010 0100 1000;
※ 각 작업자 프로세스를 개별로 CPU0~CPU4에 바인딩
worker_processes 2;
worker_cpu_affinity 0101 1010
※ 첫 번째 작업자 프로세스를 CPU0 / CPU2에 바인딩하고 두 번째 작업자 프로세스를 CPU1 / CPU3에 바인딩
worker_cpu_affinity auto 01010101;
※ 자동으로 바인딩 가능한 CPU를 제한 할 수 있습니다.
3. 프로세스당 동시 작업 연결 수 : worker_connections
- 작업자 프로세스에서 열 수있는 최대 동시 연결 수를 설정합니다.
다음으로 cpu와 밀접한 변수는 worker_connections 수 입니다. 보통 CPU 코어수 * 1024 정도를 권장을 합니다.
하나의 cpu코어가 처리할 수 있는 량을 고려하여 적절한 숫자를 입력하면 됩니다.
user nginx; # default nobody
worker_processes auto; # [auto | cpu core 수]
worker_rlimit_nofile 204800;
worker_cpu_affinity auto;
pid /var/run/nginx.pid;
error_log /var/log/nginx.error_log debug;
# [ debug | info | notice | warn | error | crit ]
#
events {
worker_connections 8192; [4096 ~ 8192 정도 : cpu 코어수 * 1024개 권장]
multi_accept on;
use epoll;
# use [ kqueue | epoll | /dev/poll | select | poll ];
# accept_mutex on;
}
http {
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 15;
#
gzip on;
gzip_http_version 1.0;
gzip_proxied any;
gzip_min_length 500;
gzip_disable "MSIE [1-6]\.";
gzip_types text/plain text/xml text/css text/comma-separated-values text/javascript application/x-javascript application/atom+xml;
upstream backend {
server backend1.example.com max_fails=3 fail_timeout=3s slow_start=15s;
server backend2.example.com max_fails=3 fail_timeout=3s slow_start=15s;
server spare.example.com:80 backup;
keepalive 1024;
}
server {
listen one.example.com backlog=20480 reuseport;
server_name one.example.com www.one.example.com;
.... 생략 ....
location / {
proxy_pass http://backend;
proxy_http_version 1.1;
proxy_set_header Connection "";
}
}
..... 생략 ....
server {
}
}
[추가 설명] - worker_processes auto
worker_processes auto; 일반적으로 auto를 사용하면 자동으로 설정을 하므로 관리가 쉽습니다.
multi_accept on – 작업자 프로세스는 한 번에 하나의 새 연결을 승인합니다 (기본값:off). 활성화 된 경우 작업자 프로세스는 한 번에 모든 새 연결을 수락합니다.
accept_mutex off – 모든 작업자 프로세스는 새 연결에 대해 알림을받습니다 (NGINX 1.11.3 이상 및 NGINX Plus R10 이상에서는 기본값:off). 활성화되면 작업자 프로세스가 차례대로 새 연결을 수락합니다. 높은 부하에서 유용 할 수 있습니다.
reuseport; 를 사용하는 경우는 종료된 소켓을 재사용하게 되므로 빠른 처리가 가능하며 소켓의 사용여부에 대한 Lock을 관리하는 "accept_mutex off "로 설정합니다.
[추가 설명] - upstream을 활용한 장애 처리
Nginx와 Was를 연동하여 운영 할때 Was를 재기동하면 nginx로 유입된 요청이 Was로 전달되어 장애가 발생 됩니다.
이런 상황은 Tomcat과 같은 jvm과 컨테이너는 재기동시 Port를 오픈하는 시간과 Java 객체들이 JVM으로 로딩 되는 시간과 gap이 발생합니다. 이때 Was는 외부 Port를 오픈하여 응답을 받아 들이려고 하고 JVM에는 Object가 로딩이 되지 않은 상태 입니다. nginx는 입장에서는 Was의 health 상 문제가 없다고 판단하고 유입된 요청을 was로 전달 하게 됩니다. 이때 웹서비스는 순간적으로 무응답 또는 장애가 발생 됩니다.
이런 문제를 해결하기 위해서는 upstream의 옵션을 이용하거나 "health_check"를 이용 할 수 있습니다.
1) upstream 의 Passive health checks 기본값으로 max_fails =1 fail_timeout = 10s.로 장애가 생기면 10초 정도의 delay가 발생되고 빠른 전환이 가능하다. max_fails=3 fail_timeout=3s; 로 장애 재시도와 장애 전환 시간을 줄일수 있다.
2) upstream slow_start=15s; 설정
Nginx의 백엔드 WAS서버들이 재기동 되는 경우 inatance가 오픈 되는데 10~20초의 Delay가 생기는 경우를 고려하여 slow_start 를 활용하여 WAS 재기동시 장애를 줄일수 있습니다.
(Tomcat의 경우 app의 서비스 포트 오픈은 컨테이너가 기동되기 전에 오픈 되므로 서비스 오류가 발생 됩니다.)
3) keepalive 1024;
keepalive 연결수는 upstream에서 처리 할 수 있는 량을 고려하여 처리 합니다.
[참고 upstream 관련 추가 설명]
능동적인 health check 하는 사례 (Active Health Checks with NGINX Plus)
Nginx Plus에서는 능동적으로 health_check 모듈을 통해 능동적인 상태 체크가 가능합니다. 설정된 interval 주기 마다 특정 URL을 호출하여 상태 체크를 할 수 있습니다.
stream {
# ...
server {
listen 1234;
proxy_pass stream_backend;
health_check interval=2s passes=2 fails=3; health_check_timeout 5s;
}
}
http {
# 일반적인 health 방식
upstream backend {
server backend1.example.com max_fails=3 fail_timeout=3s slow_start=15s max_conns=200;
server backend2.example.com max_fails=3 fail_timeout=3s slow_start=15s max_conns=200;
server spare1.example.com:80 backup;
server spare2.example.com:80 backup;
keepalive 1024;
queue 3000 timeout=30s;
}
server {
# 능동적인 health 방식.
location / {
proxy_pass http://backend;
health_check interval=2s fails=2 passes=5 uri=/ match=welcome;
}
}
# status is 200, content type is "text/html", # and body contains "Welcome to nginx!"
match welcome {
status 200;
header Content-Type = text/html;
body ~ "Welcome to nginx!";
}
}
upstream의 연결 관련 health 체크와 max_conns를 활용하면 queue를 통해 동시 트레픽의 완충 역할을 하여 웹서버의 순간적인 과부하를 방지 할 수 있습니다.
그러나 Nginx의 처리 가능한 queue 이상의 트레픽이 지속적으로 유발시에는 처리가 불가능한 상황이 발생 합니다.
이때를 위해서 server spare2.example.com:80 backup; 와 같은 백업 서버를 활용 할 수 있습니다.
max_fails=3 fail_timeout=3s slow_start=15s
max_conns=200;
[기타]
- docs.nginx.com/nginx/admin-guide/load-balancer/tcp-health-check/
1. 디스크의 I/O 병목 줄이기
2. 프로세스 처리량 늘리기 (Process)
3. TCP 관련 처리량 늘리기
4. 메모리 및 CPU 튜닝하기 (Processor)
5. 마이크로캐싱
6. 로그 부하 줄이기
7. Dos, DDos 방어 설정
'InfraPlatform' 카테고리의 다른 글
| [꿀팁]고성능 Nginx를위한 보안(7)-DoS, DDoS 공격 방어 설정 (1) | 2021.01.18 |
|---|---|
| [꿀팁] 고성능 Nginx를위한 튜닝(6)-로그 부하 줄이기 (0) | 2021.01.13 |
| [꿀팁]고성능 Nginx를위한 튜닝(5)-마이크로캐싱 (2) | 2021.01.09 |
| [꿀팁] 고성능 Nginx를위한 튜닝 - (3) TCP 관련 처리량 늘리기-리눅스커널튜닝 (4) | 2020.12.28 |
| [꿀팁] 고성능 Nginx를위한 튜닝 - (2) 프로세스 처리량 늘리기 (0) | 2020.12.27 |
| [꿀팁] grubby를 이용한 grub2 커널 부팅 순서 변경하기 (0) | 2020.12.26 |
| OpenSSL/TLS 1부- SSL(Secure Socket Layer) 보안 소켓 계층 이해 (0) | 2020.12.13 |