실시간 수집 분석을 위한 아파치 피노(Apache Pinot)
대규모 유통 과정의 데이터를 실시간으로 수집하고 분석하는데 필요한 기술로 대용량의 분산 스트리지가 필요하다면 Apache Pinot을 사용하여 문제를 해결 할 수 있습니다. Apache Pinot kafka와 같은 실시간 데이터 stream 기술과 함께 필요한 데이터를 저장하고 조회가 가능한 분산 저장소 입니다.
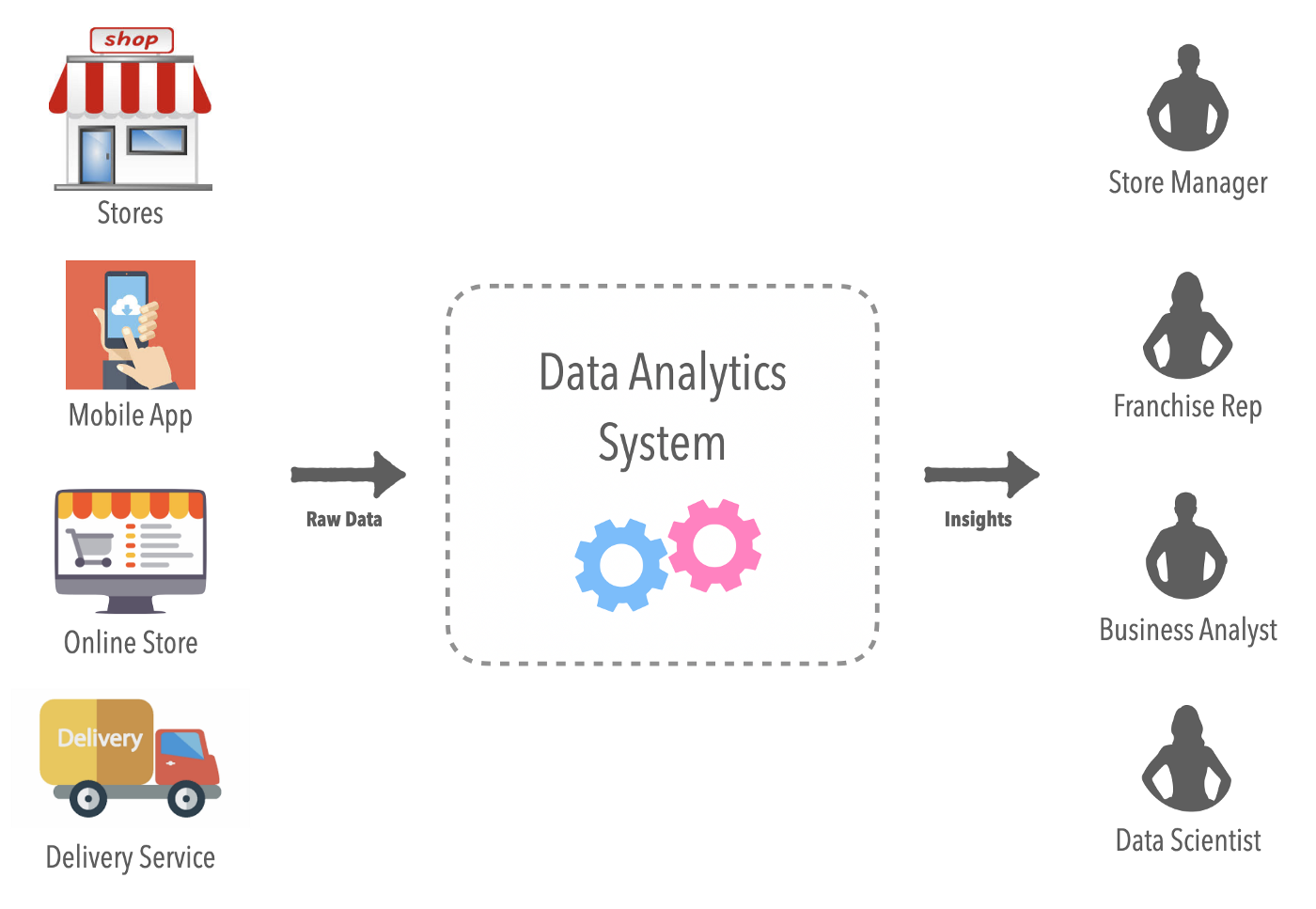
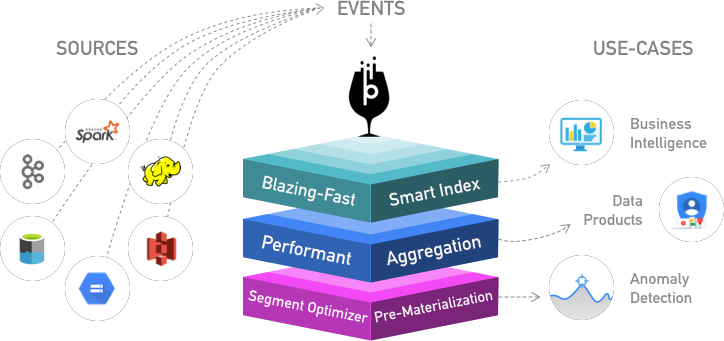
실시간 수집 분석 DB Apache pinot
( OLAP :Online analytical processing queries)
Apache Pinot 개요
Realtime distributed OLAP datastore, OLAP queries with low latency
Apache Pinot은 지연 시간이 짧은 확장 가능한 실시간 분석을 제공하는데 사용되는 실시간 분산 OLAP 데이터 저장소입니다. 배치 데이터 소스(예: HDFS, S3, Azure Data Lake, Google Cloud Storage) 및 스트리밍 소스(예: Kafka)에서 데이터를 수집할 수 있습니다. Pinot은 필요에 따라 더 큰 데이터 세트와 더 높은 쿼리 속도로 확장할 수 있도록 수평 확장되도록 설계되었습니다.
Pinot의 특징
• 수평 확장 가능한 내결함성 아키텍처
• 스트리밍 플랫폼에서 거의 실시간 수집 기능을 포함
- 거의 실시간 스트림 데이터 수집 과 Hadoop의 배치 수집 지원
• Pinot은 최신 데이터에 대한 빠른 쿼리를 제공
- 쿼리 및 세그먼트 메타데이터를 기반으로 쿼리/실행 계획을 최적화 기능
• 플러그인 가능한 인덱싱 기술
- Sorted Index, Bitmap Index, Inverted Index
• 다양한 압축 방식을 가진 컬럼 기반 데이터베이스 지원
- Run Length, Fixed Bit Length 등
• 대화형 쿼리와 Rest-API 를 통한 프로그래밍 방식의 SQL 인터페이스를 제공
• 다중값 필드 지원
실시간 데이터 처리를 위한 에코시스템 구성 사례 (Linkedin)
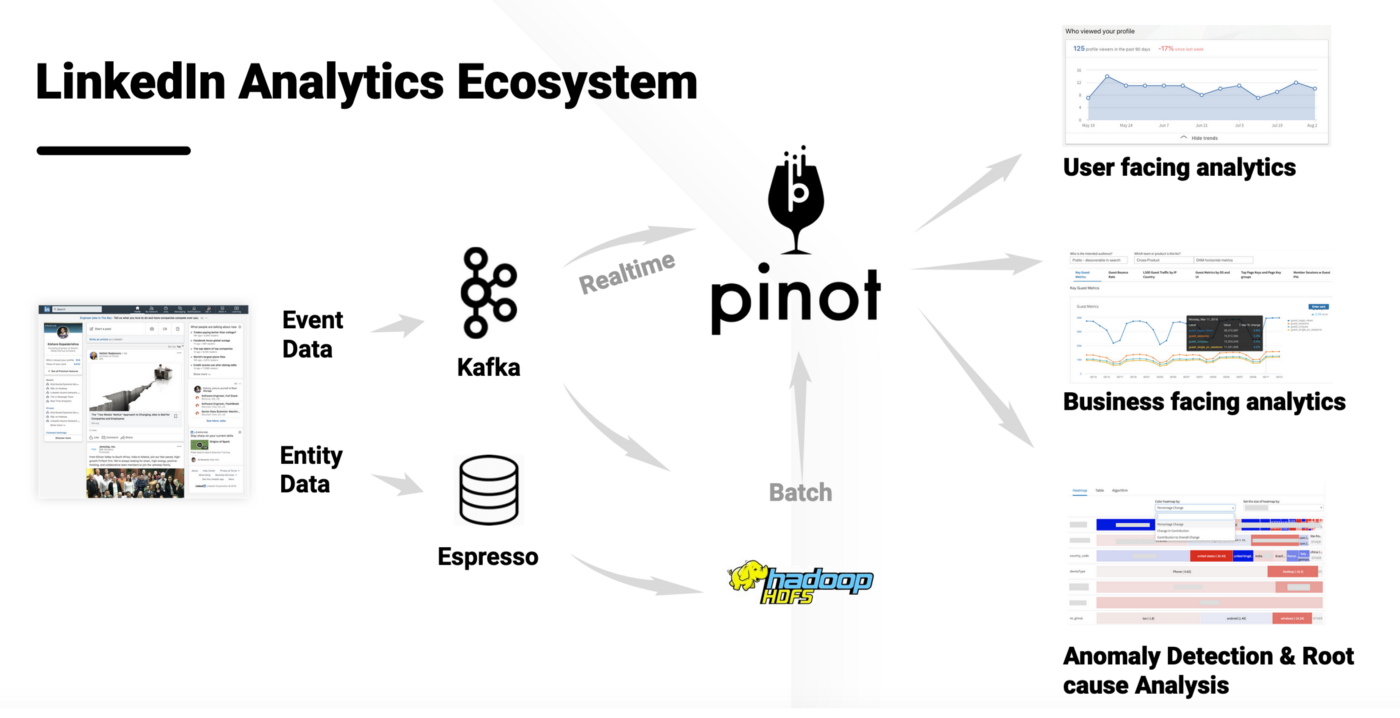
Pinot은 다차원의 메트릭이 있는 시계열 데이터를 쿼리하는 데 적합합니다. SQL을 이용해서 쉽게 데이터를 조회 할 수 있습니다.
SELECT sum(clicks), sum(impressions)
FROM AdAnalyticsTable
WHERE ((daysSinceEpoch >= 17849
AND daysSinceEpoch <= 17856))
AND accountId IN (123456789)
GROUP BY daysSinceEpoch TOP 100
Pinot의 단점 과 한계
Pinot은 많은 차원과 메트릭이 있는 시계열 데이터를 쿼리하는 데 매우 적합합니다.
기존 데이터베이스와 같이 실제 데이터 저장소의 소스로 사용할 수 없으며 데이터를 변경할 수 없고 검색 엔진을 대체할 수 없습니다.
즉, 전체 텍스트 검색이 지원되지 않습니다. 쿼리는 여러 테이블에 걸쳐 있을 수 없습니다.
최신 Pinot는 또한 간단한 DDL을 지원하여 파일에서 직접 테이블에 데이터를 삽입합니다
통합 실시간 OLAP 데이터 저장소 활용
NoSQL에서 RDBMS에 이르기까지 다양한 형식의 여러 데이터베이스에서 Pinot로 수집되는 수많은 Kafka 항목으로 데이터 이벤트를 스트리밍하도록 Pinot는 모두 Kafka와 매우 잘 작동합니다.
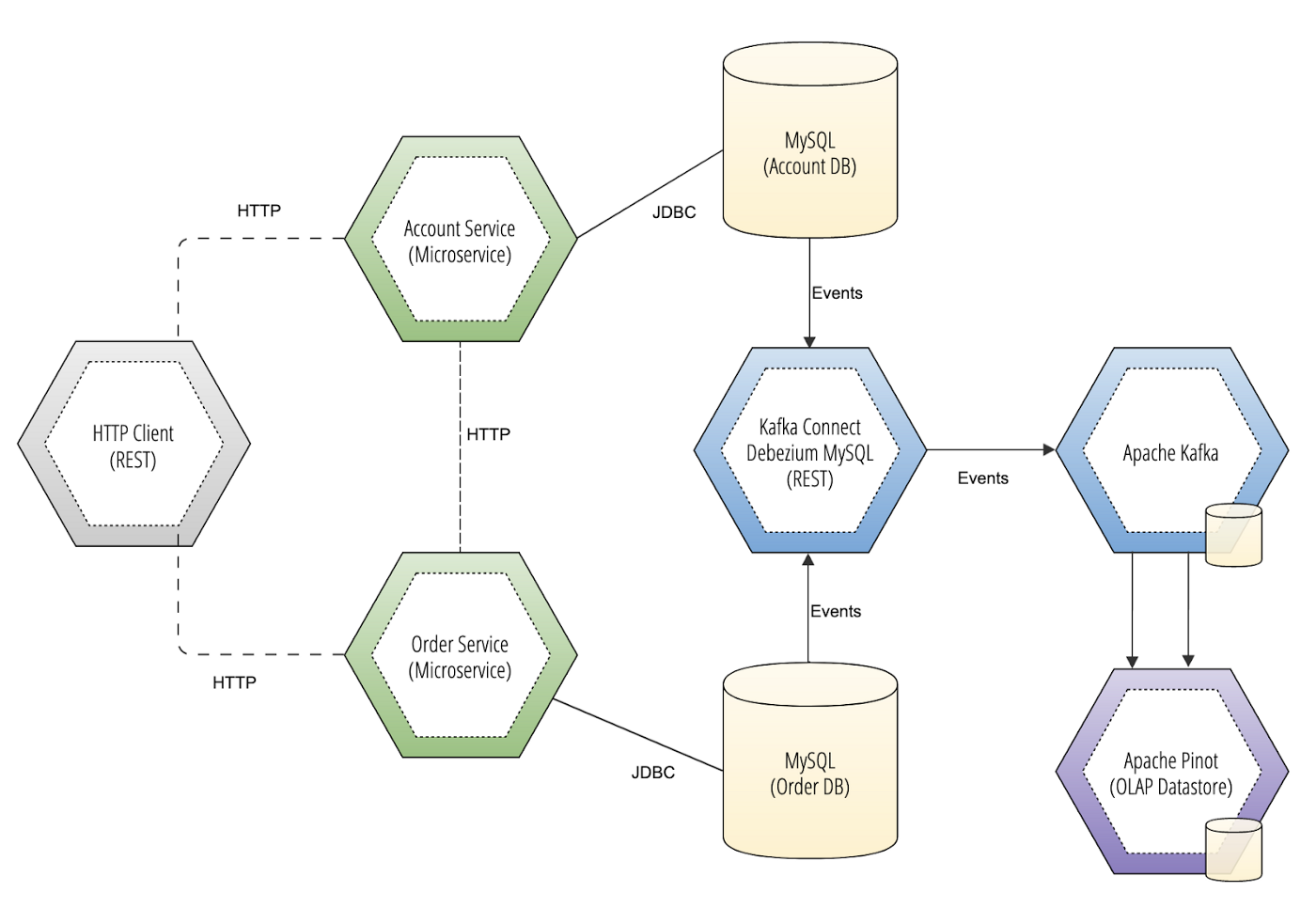
통합 실시간 모니터링 활용
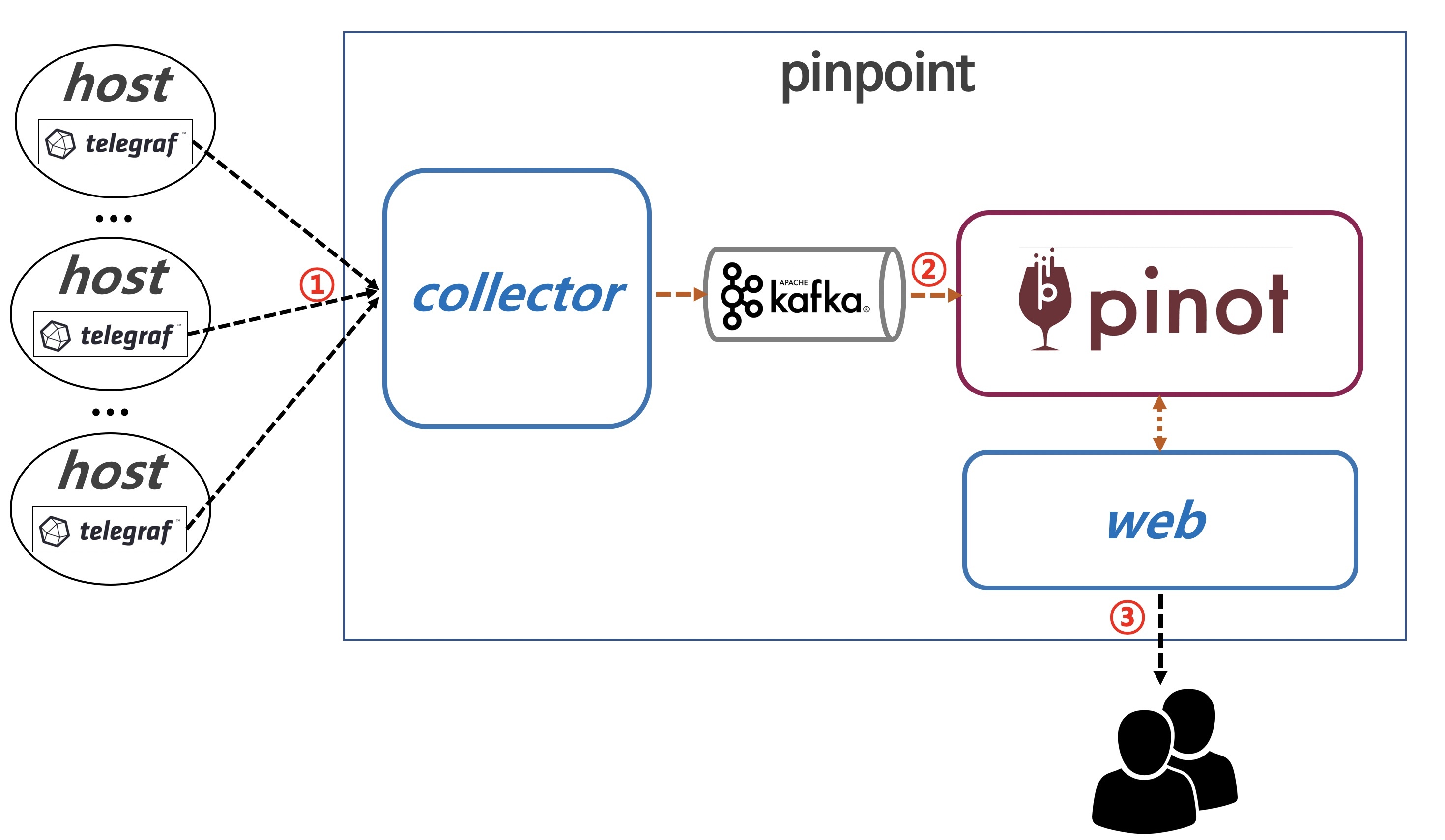
Telegraf 에이전트 로 시스템 메트릭 데이터를 수집하고 collector에 전달하여 pinot에 데이터를 저장합니다. pinot web에서는 저장된 system metric 데이터를 확인 할 모니터링 환경을 만들수 있습니다.
(Telegraf는 CPU, 디스크용량, 메모리용량, Inode상태, 시스템 부하등의 system Metric을 수집할 수 있습니다.)
① telgegraf agent에서 system metric 데이터를 collector에 전달한다.
② collector는 kafka에 데이터를 전송하여 pinot에 데이터를 저장한다.
③ web은 pinot에서 데이터를 조회하여 화면으로 데이터를 보여준다.
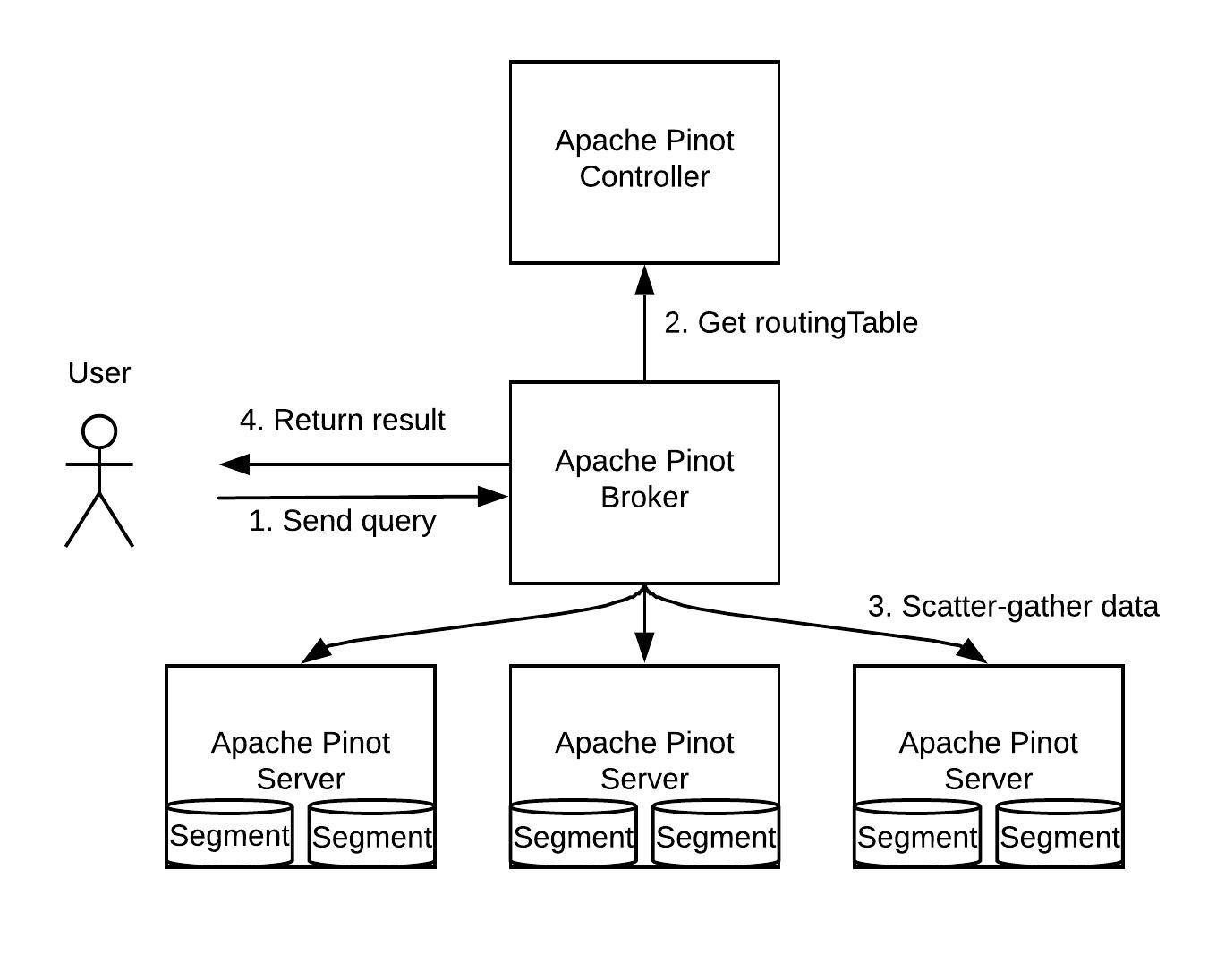
아파치 Pinot 의 분산 시스템 컴포넌트 구성
- Pinot 컨트롤러 : 메타데이터 관리 ( Configs and Schemas)
- Pinot 브로커 : 각 클라이언트의 요청권 쿼리를 서버로 보내고 응답합니다.
- Pinot 서버 : 온라인/오프라인 세그먼트를 저장하고 데이터의 쿼리를 처리하는 역할을 합니다.
실시가의 스트림 (Kafka, EventHub)으로 수집된 인메모리 수집 세그먼트를 저장소에 저장합니다. Pinot 테이블(Helix 파티션)의 파티션을 호스팅 합니다.
- 미니언(옵션) : Helix Task 프레임웍으로 세그먼트를 생성, 제거, 병합 합니다.
Pinot 설치 및 작동 방법
Install JDK11 or higher (JDK16 is not yet supported)
For JDK 8 support use Pinot 0.7.1 or compile from the source code.
바이너리를 사용하여 설치 및 실행 방법 https://docs.pinot.apache.org/basics/getting-started/running-pinot-locally
$ VERSION=0.10.0
$ wget https://downloads.apache.org/pinot/apache-pinot-$VERSION/apache-pinot-$VERSION-bin.tar.gz
$ tar vxf apache-pinot-*-bin.tar.gz
$ cd apache-pinot-*-bin
$ bin/quick-start-batch.sh
도커 컨테이너를 사용하여 설치 및 실행 방법 https://docs.pinot.apache.org/basics/getting-started/running-pinot-in-docker
$ docker run \
-p 9000:9000 \
apachepinot/pinot:0.9.3 QuickStart \
-type batch
[참조]
#apache pinot (아파치 피노)
https://pinpoint-apm.gitbook.io/pinpoint/documents/system_metric
https://redpanda.com/blog/streaming-data-apache-pinot-kafka-connect-redpanda
https://pinot.apache.org/blog/2021/01/08/DevBlog-DebeziumCDC/
'BigData' 카테고리의 다른 글
| 실시간데이터처리 Cloud-Native Singlestore DB 특징과 Linux 설치 가이드 (79) | 2023.10.04 |
|---|---|
| [SQLite] SQLite 설치하기 (0) | 2023.03.29 |
| 실시간 데이터 처리를 위한 Redpanda와 pinot 활용 (0) | 2022.12.22 |
| [초보] SQL 기초 모음 - DELETE(1) (0) | 2022.08.11 |
| [초보] SQL 기초 모음 - UPDATE(1) (0) | 2022.08.11 |
| [SQLite] Sqlite transaction ACID 개념 (0) | 2022.08.10 |
| [SQLite] Sqlite transaction 처리문 - BEGIN TRANSACTION (0) | 2022.08.10 |