728x90
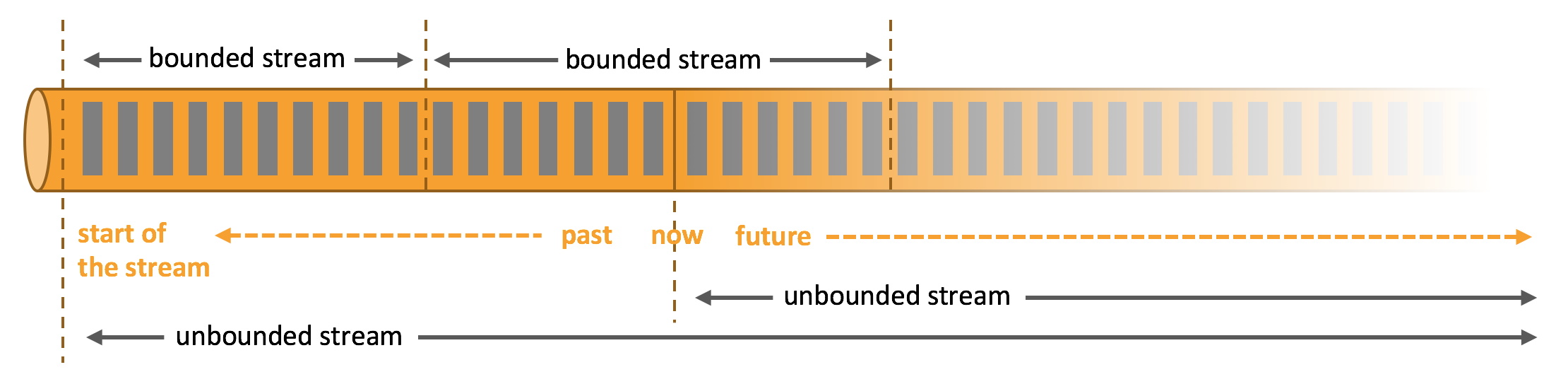
Process Unbounded and Bounded Data
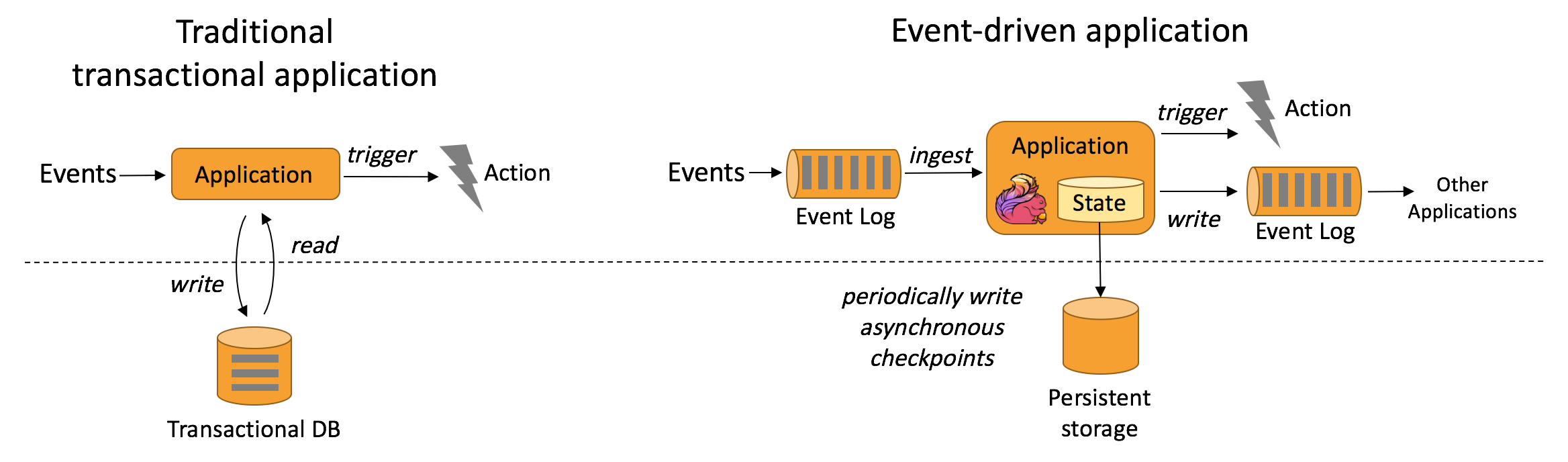
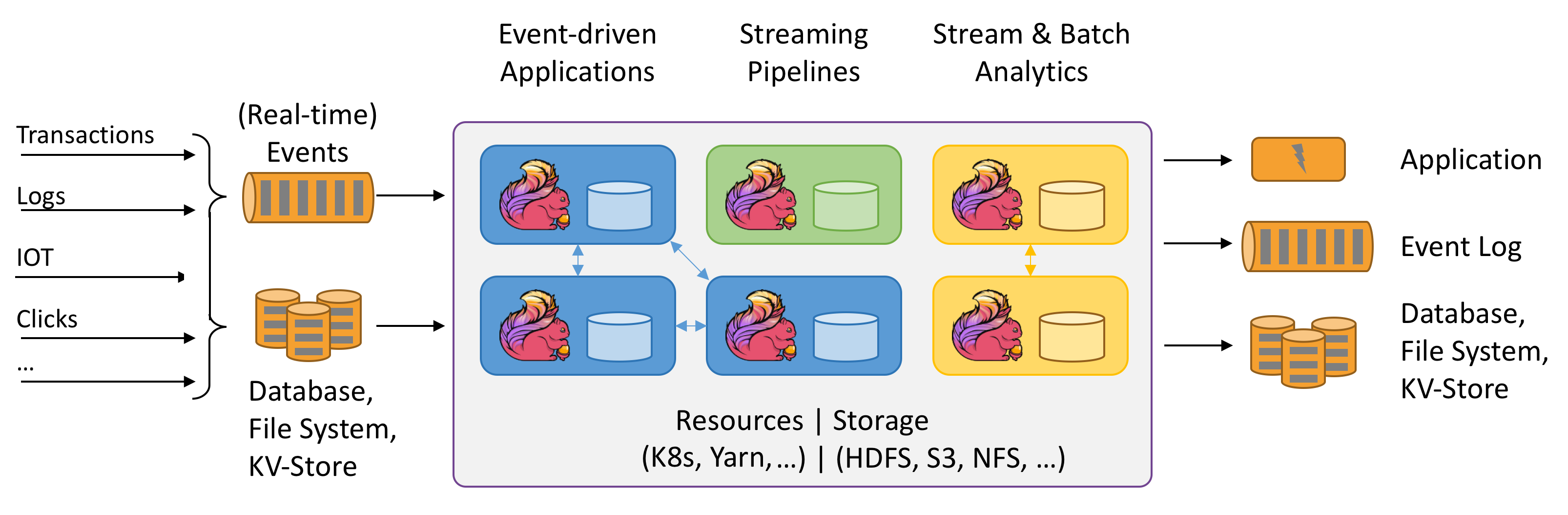
Any kind of data is produced as a stream of events. Credit card transactions, sensor measurements, machine logs, or user interactions on a website or mobile application, all of these data are generated as a stream.
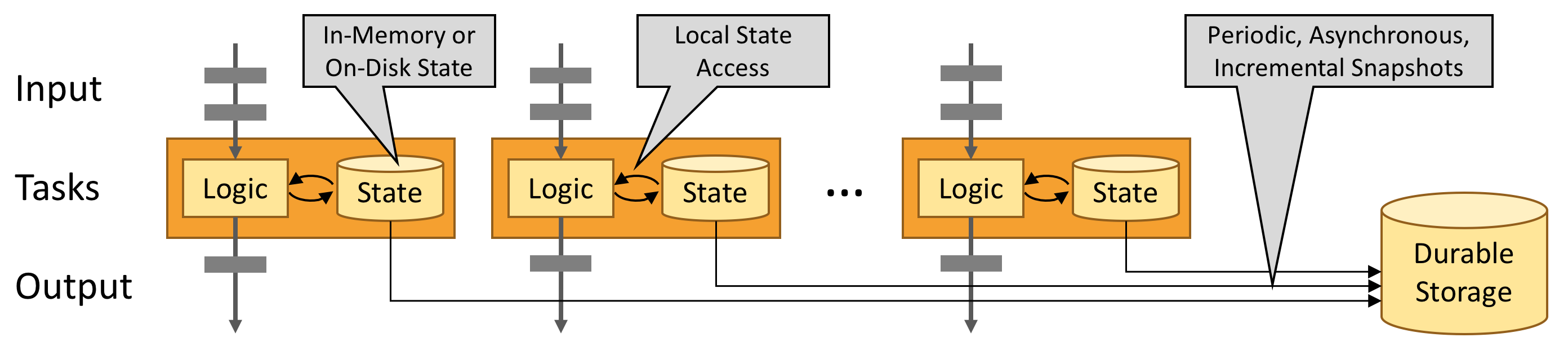
Apache Flink는 무한하고 한정된 데이터 스트림을 통한 상태 저장 계산을위한 프레임 워크 및 분산 처리 엔진입니다 . Flink는 모든 일반적인 클러스터 환경 에서 실행되도록 설계되었으며 메모리 속도 와 규모 에 관계없이 계산을 수행 합니다 .
Flink는 Hadoop YARN , Apache Mesos 및 Kubernetes 와 같은 모든 공통 클러스터 리소스 관리자와 통합 되지만 독립 실행 형 클러스터로 실행되도록 설정할 수도 있습니다.
https://hub.packtpub.com/apache-flink-version-1-6-0-released/
https://flink.apache.org/
728x90
반응형
'BigData' 카테고리의 다른 글
| zookeeper / firewalld 설치 (0) | 2020.03.08 |
|---|---|
| (아나콘다 기초) Anaconda install (1) (0) | 2019.06.22 |
| hadoop 3.0에 설치되는 시스템 정리 (0) | 2018.10.21 |
| 빅 데이터 애플리케이션을위한 NoSQL 데이터베이스의 효과적인 크기 조정 (0) | 2018.07.24 |
| Mariadb Install (2) - 설치 & 환경설정 installation (0) | 2017.11.15 |
| Mariadb Install (1) - 패키지 다운로드 download Script for packages (0) | 2017.11.13 |
| Oracle 11g 라이선스 정책 (0) | 2017.07.18 |