DevOps
[핵심]정규 표현식에 다중 공백과 한글이 있는 문자열 처리
IT오이시이
2023. 8. 9. 07:21
728x90

[핵심] 정규 표현식
1. 파이썬에서 정규 표현식 이용하기
2. PHP에서 정규표현식 (한글 처리)
[핵심]정규 표현식에 다중 공백과 한글이 있는 문자열 처리
* 프로그램의 문자 패턴 처리를 위한 정규 표현식의 기초와 한글 처리에 대하여 알아보고자 합니다
* 정규표현식(Regular Expression)으로 한글 문자열을 처리하는 쉬운 예시입니다.
문자열에 한글이나 특수문자가 있는 문자열과 공백이 없거나 하나 이상 있는 경우를 찾을 수 있습니다.
[ 목 차 ]
1. 정규표현식에 대한 개념과 정규식 메타문자 기초를 설명한다.
2. 정규표현식을 이용한 문자열을 분리하는 방법을 소개한다.
3. 정규식을 이용한 한글 문자 인식에 대한 처리 방법을 소개한다.
4. 파이썬 과 PHP로 작성된 정규식 표현 예시를 설명한다.
(개발 언어는 모두 유사하므로 다른 언어도 참고 바랍니다.)
정규표현식 (Regular Expression)
정규 표현식(Regular Expression 또는 regex)은 문자열 패턴을 검색, 추출 및 조작하기 위해 사용되는 텍스트 처리 도구입니다. 이를 사용하여 문자열 내에서 특정 패턴을 찾거나 대체하는 작업을 수행할 수 있습니다.
[문자처리시 자주 사용하는 정규표현식 기초]
1. 문자를 처리하기 위해 사용한 주요 정규표현식 메타 문자의 설명은 아래와 같습니다.
1) \s : space, tab, blank : 하나만 있는 경우
\s+ : 하나 이상 space, tab 있는 경우
\s{0,3} : 없거나 3개 이하인 경우
\s{0,} : 없거나 0개 이상이며 몇 개인지 모르는 경우 (여기 답을 찾는데 중요한것)
2) \w : word 문자열에 일치합니다. [A-Za-z0-9_]
\W : 비단어 문자열에 일치 합니다. [가-힣] 같은 것들을 말합니다.
\b : 단어의 경계를 찾으며 사이즈가 0입니다. (This match is zero-length of word boundary.)
3) \d : 숫자로만 이루어진 문자열 [0-9]{0,10} 도 숫자 영역을 찾습니다.
위의 내용 외에 일반적으로 다음과 같은 것을 주로 사용합니다.
* [a-zA-Z0-9]{0,10} : 알파벳 소.대문자, 숫자로 이루어진 10자 이하의 문자열을 찾는 경우
* [0-9]{0,10} : 0~9로 구성된 10자 이하의 숫자 열을 찾는 경우
[Regular express을 사용한 Email Address ]

/pattern/ : 정규식의 블럭으로 안에 있는 정규식 (=패턴)을 인식하게 한다.
\w : [a-zA-Z0-9]+ 와 같은 문자열을 나타낸다.
[ ._%+-] : Meta문자가 아닌 실제 매칭되는 문자임
[pattern]+ : +는 Meta문자이며 괄호안의 문자들을 반복할수 있다는 표현이다.
[pattern]+@ : @는 실제 이메일 주소에서 사용하는 @ 문자 이다.
[pattern]+\. : \. 역슬레시는 메타문자와 문자를 구별하기 위해 사용하여 콤마(.) 문자로 인식하도록한다.
[pattern]{2,4} : 괄호안의 문자를 2~4개로 구성된 문자열을 인식하게 한다.
[Regular express에서 사용하는 Meta character ]
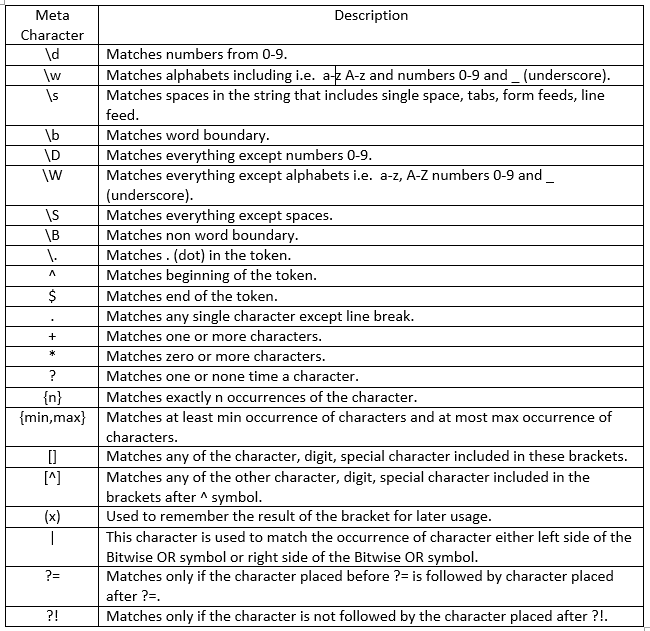
2. 다음은 정규표현식의 표현 중 다중 매칭된 문자열을 추출하는 것입니다.
- php 에서 preg_split을 해도 되는데 여기서는 preg_match를 사용했습니다.
/ (추출할 정규식1) 일반문자열 (추출할 정규식2) /1) 괄호 "/ /"는 정규식 전체 단락의 범위를 정합니다.
2) 괄호 "( )"는 정규식내의 변수의 범위를 정합니다.
3) 일반문자열은 전체 정규식에 찾을 문자열에 추가로 포함되어야 하는 나머지 문자열 입니다.
4) 추출할 정규식1, 2 는 매칭 이후 일치하면 리턴 되는 값입니다.
PREG_OFFSET_CAPTURE : 일치하는 모든 항목에 대해 추가 문자열 오프셋 (바이트 단위)도 반환
| preg_match('/(foo)(bar)(baz)/', 'foobarbaz', $matches, PREG_OFFSET_CAPTURE); print_r($matches); |
| [0] => foobarbaz # PREG_OFFSET_CAPTURE 에 의해 반환됩니다. [1] => foo [2] => bar [3] => baz |
| preg_match('/(a)(b)*(c)/', 'ac', $matches); |
| [0] => ac [1] => a [2] => "" [3] => c |
PREG_UNMATCHED_AS_NULL :
| preg_match('/(a)(b)*(c)/', 'ac', $matches , PREG_UNMATCHED_AS_NULL); |
| [0] => ac [1] => a [2] => NULL [3] => c |
3. 한글 처리 정규표현식은 아래 같이 두가지 유형을 사용했습니다.
한글 정규식으로 [ㄱ-ㅣ가-힣] 과 [가-힣] 을 사용 하여 한글의 영역을 지정 할 수 있습니다.
- ([ㄱ-ㅣ가-힣]{0,}) , ([ㄱ-ㅣ가-힣]+), ([가-힣]+|\w+) 를 사용 할 수 있습니다.
# 일반적인 가나다 기준으로도 일반적인 한글을 찾을수 있습니다.
$kor_pattern1='/[가-힣]{0,}/';
# ㅏ~ ㅣ .... 가~힣 ㅣ와 가 사이의 문자들을 제외하여 한글을 찾습니다.
$kor_pattern2='/[ㄱ-ㅣ가-힣]{0,}/';
정규식에 필요한 한글 코드 범위
ㄱ ~ ㅎ: 0x3131 ~ 0x314e
ㅏ ~ ㅣ: 0x314f ~ 0x3163
가 ~ 힣: 0xac00 ~ 0xd7a3
* '|' ~ '가' 사이의 많은 문자들이 있다는 점을 고려하여 정규식을 작성합니다.
예시 #1 설명 : \s{0,} 사용한 공백 찾기와 ([가-힣]+|\w+)로 한글 문자열을 찾습니다.
$reg_pattern1='/([가-힣]+|\w+)(\s{0,}):(\s{0,})(\w+)$/';
// 한글이 포함된 문자열과 아닌 문자열을 or로 묶었습니다.
// (문자열1) (공백열1) : (공백열2) (문자열2) 로 이루어진 문장에서 문자열1,2를 리턴합니다.
// $arr_matchs[1] : 문자열1 이고 $arr_matchs[2] 문자열2 입니다.
예시 #2 설명 : (\s+|\b) 사용한 공백 처리, (\w+|\W+) 로 비문자열과 문자열 ( 한글과 영문,숫자 등) 문자열 찾기
$reg_pattern2='/(\w+|\W+)(\s+|\b):(\b|\s+)(\w+)$/';
// (문자열1) (공백열1) : (공백열2) (문자열2)
// $arr_matchs[1] : 문자열1 이고 $arr_matchs[2] 공백열1 .. 이런 순으로 $arr_matchs[4] 문자열2
* 한글 문자를 고려한 문자열 분리
$reg_pattern1='/([가-힣]+|\w+)(\s{0,}):(\s{0,})(\w+)$/'; #한글 문자열을 인식하는 정규표현식
([가-힣]+|\w+): 한글문자([가-힣]+)나 알파벳,숫자로 이루어진 단어 문자(\w+) 중 하나와 일치
\s{0,}: 공백 문자가 0회 이상 등장하는 것과 일치
: : 은 콜론 문자 ":"과 정확히 일치
\s{0,}: 공백 문자가 0회 이상 등장하는 것과 일치
(\w+) : 한 개 이상의 단어 문자 (알파벳, 숫자, 밑줄)와 일치
$ : 문자열의 끝에 위치하는 것과 일치합니다.
* 일반 워드를 이용한 단어 분리
$reg_pattern2='/(\w+|\W+)(\s+|\b):(\b|\s+)(\w+)$/';
(\w+|\W+): 단어 문자(\w+) 또는 단어 문자가 아닌 문자(\W+) 중 하나와 일치
(\s+|\b) : 공백 문자가 하나 이상 등장하거나 단어 경계(\b)와 일치
: : 콜론 문자 ":"과 정확히 일치
(\b|\s+) : 단어 경계(\b) 또는 공백 문자가 하나 이상 등장하는 것과 일치
(\w+) : 한 개 이상의 단어 문자 (알파벳, 숫자, 밑줄)와 일치4. 파이썬 과 PHP로 작성된 정규식 표현 예시를 설명한다.
4.1 파이썬으로 작성한 정규식 소스 : regular.py
import re
in_array = ["가나 : 123566", # 한글 Or 숫자
"가나힟 : 가123566", # 한글 + 숫자
"가뿱뿕힣 : 가123566", # 한글 + 숫자
"가나Any : 가Any123566", # 한글 + 영어 + 숫자
"abcㄱㄴㄷ : abcㄱㄴㄷ31213", # 한글자음 + 영어 + 숫자
"가ㄹ나 : 가ㄱㄴ123566", # 한글자음 + 숫자
"abc : 1tab312312223123", # 공백 + TAB
"탭탭 : tabtabafasdf2223123", # 공백 + TAB
"12349 : 012312223123" ] # 숫자
reg_pattern1 = r'([가-힣]+|\w+)(\s{0,}):(\s{0,})(\w+)$' # 한글 문자열을 인식하는 정규표현식
print(" Result case 1-------------------------------")
for key, arr_value in enumerate(in_array):
#print("[%s] -> [%s] " %(key , arr_value) )
match = re.match(reg_pattern1, arr_value)
if match:
print(f" {key} > Result Success ==== : '{match.group(1)}', '{match.group(4)}' ")
else:
print(f" {key} > Result Failed ---- : '{match}' <<- {arr_value}")
reg_pattern2 = r'(\w+|\W+)(\s+|\b):(\b|\s+)(\w+)$'
print("\n Result case 2-------------------------------")
for key, arr_value in enumerate(in_array):
#print("[%s] -> [%s] " %(key , arr_value) )
match = re.match(reg_pattern2, arr_value)
if match:
print(f" {key} > Result Success ==== : {key} : '{match.group(1)}', '{match.group(4)}' ")
else:
print(f" {key} > Result Failed ---- : '{match}' <<- {arr_value}")
4.2 PHP로 작성한 정규식 소스 : regular.php
공백이 포함된 문자열에서 문자열(한글)을 추출하는 것을 테스트 하는 소스 입니다.
한글이 포함된 경우와 일반적인 문자열에서 공백을 제외하는 경우에 대한 테스트로 동일한 결과가 나옵니다.
$reg_pattern1='/([가-힣]+|\w+)\s{0,}:\s{0,}(\w+)$/'; #한글 문자열을 인식하는 정규표현식
$reg_pattern2='/(\w+|\W+)(\s+|\b):(\b|\s+)(\w+)$/';
----------------------------
<?php
$in_array = array("가나 : 123566", // 한글 Or 숫자
"가나힟 : 가123566", // 한글 + 숫자
"가뿱뿕힣 : 가123566", // 한글 + 숫자
"가나Any : 가Any123566", // 한글 + 영어 + 숫자
"abcㄱㄴㄷ : abcㄱㄴㄷ31213", // 한글자음 + 영어 + 숫자
"가ㄹ나 : 가ㄱㄴ123566", // 한글자음 + 숫자
"abc : 1tab312312223123", // 공백 + TAB
"탭탭 : tabtabafasdf2223123", // 공백 + TAB
"12349 : 012312223123" ); // 숫자
print " Result case 1-------------------------------\n";
$reg_pattern1='/([가-힣]+|\w+)(\s{0,}):(\s{0,})(\w+)$/'; #한글 문자열을 인식하는 정규표현식
foreach ($in_array as $key => $arr_value ) {
//print " > $arr_value ";
$ret_value = preg_match($reg_pattern1, $arr_value, $arr_matchs);
//print " >> $ret_value \n";
//print_r($arr_matchs );
if ($ret_value){
print "$key > Result Success ==== : '$arr_matchs[1]', '$arr_matchs[4]' \n";
}else{
print "$key > Result Failed ---- : '$arr_matchs' <<- $arr_value\n";
}
}
print " Result case 2-------------------------------\n";
$reg_pattern2='/(\w+|\W+)(\s+|\b):(\b|\s+)(\w+)$/';
foreach ($in_array as $key => $arr_value ) {
//print " > $arr_value ";
$ret_value = preg_match($reg_pattern2, $arr_value, $arr_matchs);
//print " >> $ret_value \n";
//print_r($arr_matchs );
if ($ret_value){
print "$key > Result Success ==== : '$arr_matchs[1]', '$arr_matchs[4]' \n";
}else{
print "$key > Result Failed ---- : '$arr_matchs' <<- $arr_value\n";
}
}
?>4.3. 정규식 소스 실행 결과
파이썬과 PHP로 작성한 정규식 예시의 결과는 각 언어별 함수의 활용에 따라 차이가 있을수 있으나 결과는 유사하게 나옵니다.
# 다음과 같이 파이썬과 PHP를 실행하면 같은 결과를 출력합니다.
[root@localhost ~]# php regular_express.php | grep Result
[root@localhost ~]# python.exe regular_express.py
Result case 1-------------------------------
0 > Result Success ==== : '가나', '123566'
1 > Result Success ==== : '가나힟', '가123566'
2 > Result Success ==== : '가뿱뿕힣', '가123566'
3 > Result Success ==== : '가나Any', '가Any123566'
4 > Result Success ==== : 'abcㄱㄴㄷ', 'abcㄱㄴㄷ31213'
5 > Result Success ==== : '가ㄹ나', '가ㄱㄴ123566'
6 > Result Success ==== : 'abc', '1tab312312223123'
7 > Result Success ==== : '탭탭', 'tabtabafasdf2223123'
8 > Result Success ==== : '12349', '012312223123'
Result case 2-------------------------------
0 > Result Success ==== : 0 : '가나', '123566'
1 > Result Success ==== : 1 : '가나힟', '가123566'
2 > Result Success ==== : 2 : '가뿱뿕힣', '가123566'
3 > Result Success ==== : 3 : '가나Any', '가Any123566'
4 > Result Success ==== : 4 : 'abcㄱㄴㄷ', 'abcㄱㄴㄷ31213'
5 > Result Success ==== : 5 : '가ㄹ나', '가ㄱㄴ123566'
6 > Result Success ==== : 6 : 'abc', '1tab312312223123'
7 > Result Success ==== : 7 : '탭탭', 'tabtabafasdf2223123'
8 > Result Success ==== : 8 : '12349', '012312223123'
이상입니다.
[핵심] 정규 표현식
1. 파이썬에서 정규 표현식 이용하기
2. PHP에서 정규표현식 (한글 처리)
728x90
반응형