(기술)인공지능과 빅데이터 분석을 위한 고성능 분산DBMS SingleStoreDB

(기술)인공지능과 빅데이터 분석을 위한 고성능 분산DBMS SingleStoreDB
빅데이터와 인공지능의 보편화
최근 빅데이터와 인공지능으로 데이터 수집과 관리 기술을 많은 기업에서 사용할 만큼 보편화 되어 있습니다.
그러나 방대하고 다양한 데이터를 처리하기 위해서 도입되는 오픈소스 기반의 데이터 기술들은 데이터 엔지니어, 데이터 사이언티스트등과 같은 고급 기술인력들을 요구하고 있습니다.
이러한 기술 인력은 부족하고 관련 기술의 난이도가 높을 수록 데이터를 관리하고 생산하는 Cost가 실제 데이터를 활용한 서비스를 만드는데 커다란 장벽으로 인식 될 수 있습니다.
앞으로 기술의 발전속도 만큼 더 빠르고 방대한 데이터들이 생겨 날 수록 데이터 기술은 더욱 효율화가 필요하고 더 간단하게 데이터를 활용하는 접근성( Accessibility )과 편리성이 높아야 할 것입니다.
singlestore 를 이용한 GPT이용
최근 chatGPT를 이용한 프롬프트 엔지니어링 과정을 보면 내부 데이터와 GPT API(LLM)를 이용합니다.
GPT를 이용 할 지식 데이터 구축 과정으로 문서(Document)에서 텍스트를 추출하여 벡터(Vector)데이터로 저장하고, LLM과 연계하여 데이터에서 유의미한 내용을 꺼내고 응답하는 것이 가능합니다.
과거 빅데이터와 같이 방대한 데이터가 없더라도 GPT와 연계하여 언어의 문맥을 기반으로도 데이터를 증강 할 수 있게 되었습니다. 벡터데이터(VectorData)와 GPT를 이용해서 빠르게 검색하고 응답하는 시스템도 고려 해야 합니다.
SingleStoreDB 는 벡터기반의 데이터 관리와 고속의 반복처리 그리고 GPT를 지원하는 LLM함수를 내장하고 있어서 GPT를 이용도 간단합니다.

빅데이터 시장에서 흔히 알고 있는 BigData를 기반으로한 DataLake도 주요한 키워드 이지만 실제 데이터 활용을 위해서는 다양한 데이터를 접근 할 수 있는 "DataFebric" 개념과 핵심데이터를 관리하고 빠르게 활용 가능한 "SmallData"는 더욱 중요한 과제로 남아 있습니다.
빅데이터의 르네상스 RDB의 귀환
오늘 참석한 SingleStore는 고속의 데이터를 처리하는 부분과 대용량으로 확장하는 부분 그리고 클라우드 기술에 적합한 데이터의 관리 효율성을 제공하는 솔루션이라고 보여 집니다.
Hadoop 보다 저렴한 비용의 Data Lake가 온다.
H/W의 기술 발전과 대량 생산으로 하드디스크의 시대가 지나고 SSD의 시대가 오면서 저렴한 비용으로 데이터의 접근 속도는 10배이상 빨라 졌습니다. 최근 윈도우 기동 속도를 보면 체감 하실테지만 2000년대 윈도우의 부팅 속도는 30초~1분 정도 였습니다. 그러나 최근에는 거의 수 10초에서 해결이 됩니다.
그만큼 대용량을 처리하는데 필요한 H.W의 비용도 절감 되고 처리 시간도 엄청 빨라 졌다는 것입니다. 그렇기 때문에 기존의 멀티 클러스터링 기반의 기술인 Hadoop 보다 단순 집약적인 기술 방식도 충분한 성능을 낼수 있게 되었습니다.

SingleStore의 특장점
1. Ingestion in Real time
SingleStore는 실시간 처리에 특화 되어 있습니다. 병렬 처리와 실시간 ETL 도구를 통해서 Real-time 처리 성능을 제공합니다.
2. Blazing Fast Performance
초당 1조개의 Row를 처리하고 짧은 응답 대기 시간으로 기존 RDBMS대비 10 ~ 100배 성능을 향상합니다.
( 실시간 Stream 데이터 처리 기능(ETL/CDC), 대용량 데이터 적재와 대량 데이터 분석 부하 분산이 가능)
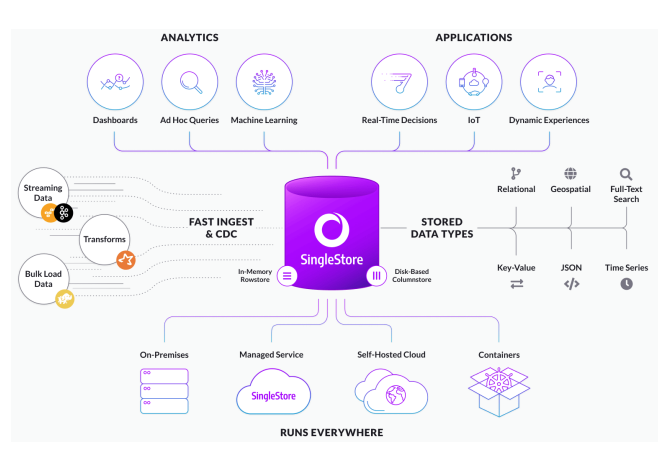
3. OLTP + OLAP를 지원
인메모리 Row 저장 기술과 디스크 기반 컬럼 스토어를 기반으로 정형, 비정형, 반정형 데이터를 취급 가능합니다.
또한 노드의 확장성이 높고 MySQL과 호환성을 제공합니다. 표준SQL 사용으로 개발과 운영도 쉽습이다.

* Rowstore (인메모리 트랜잭션)와 Columnstore (대량 입출력 트랜잭션 및 디스크I/O 최소화로 대량 분석)

4. 데이터 활용 아키텍처와 복잡성 해결
- 대부분 빅데이터 플랫폼들은 다양한 오픈소스 Data 기술을 활용하여 Data PipeLine과 복잡한 아키텍처 구조를 가지고 있습니다. 이들 시스템을 운영하기 위해서는 경험 가진 고급 기술자와 운영 노하우가 요구됩니다.
SingleStore는 Hadoop에코와 같이 전문 인력의 경험 없이 RDB 경험자도 쉽게 이용이 가능합니다. 또한 SQL에 익숙한 데이터 분석가가 직접 데이터를 활용할 수 있어 AI-Ops 같은 조직을 구성하는데 장점을 제공 할 수 있습니다.

5. SingleStore의 데이터 아키텍처 - 확장성
- 대량의 데이터 확장을 위한 분산 저장 기술로 Leaf 노드의 무한 확장이 가능하고 Aggregration노드의 computing과 Leaf노드의 Storage저장 기능을 분리하여 유연한 확장성을 가지고 있습니다.

* Aggregrator의 Computing 노드와 Leaf Node Storage 기능을 분리하여 확장 가능

6. SingleStore의 데이터 아키텍처 - Data Pipeline 지원
- 기존 Kafka, CloudStorage, Hadoop 등의 데이터 파이프라인 호환성을 제공하고 내장된 병렬 처리 기술과 트랜젝션 일관성 보장제공합니다. 또한 JSON, Avro, Parquet, CSV등의 지원하여 대량의 데이터도 쉽게 다룰 수 있습니다.
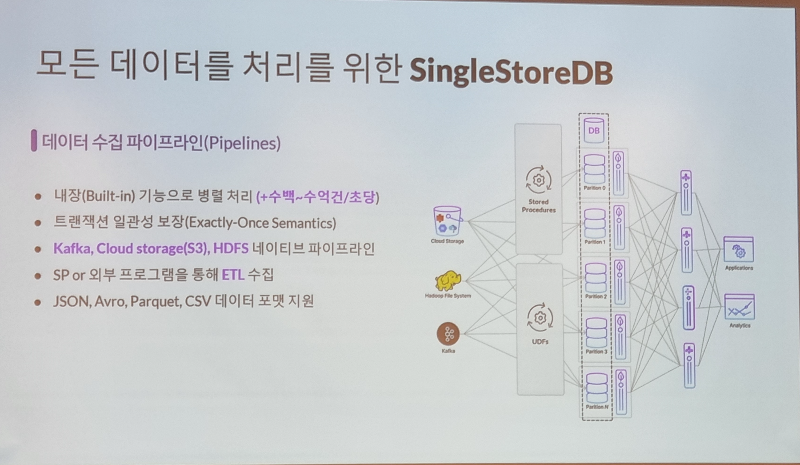
SingleStore는 Kafka connect를 이용하여 직접적으로 Kafka Data를 적재하고 전송할수 있는 인터페이스를 제공하므로 다양한 오픈소스와 연계 개발이 용이하다.
* (Kafka to DB) 내장된 Data 수집 Pipeline으로 Kafka/Confluent에서 데이터 로드/적재가 가능합니다.
* 1.Creating a Kafka Pipeline in SingleStore
CREATE DATABASE quickstart_kafka;
USE quickstart_kafka;
CREATE TABLE messages (id text);
CREATE PIPELINE quickstart_kafka AS LOAD DATA KAFKA '<kafka-cluster-ip>/test' INTO TABLE messages;
* 2. Data Load 상태를 테스트
TEST PIPELINE quickstart_kafka LIMIT 1;
* 3. Kafka to DB를 실행
START PIPELINE quickstart_kafka;
* (DB to Kafka) "SELECT ... INTO KAFKA ..."는 DB에서 Kafka로 직접 메시지를 보낼 수 있습니다.
* SELECT ... INTO KAFKA ...
- (DB to Kafka) DB에서 Kafka/Confluent로 메시지 생성이 가능
CREATE TABLE numbers(a INT, b INT, c INT);
INSERT INTO numbers(a,b,c) VALUES (10,20,30);
INSERT INTO numbers(a,b,c) VALUES (40,50,60);
INSERT INTO numbers(a,b,c) VALUES (70,80,90);
SELECT a + 10, b + 20, c + 30
FROM numbers INTO KAFKA '<Confluent Cloud broker URL>/numbers-topic'
CONFIG '{
"security.protocol":"SASL_SSL",
"sasl.mechanism":"PLAIN",
"ssl.ca.location":"<CA certificate file path>",
"sasl.username":"<CLUSTER_API_KEY>"
}'
CREDENTIALS '{"sasl.password":"<CLUSTER_API_SECRET>"}'
FIELDS TERMINATED BY ',' ENCLOSED BY '"' ESCAPED BY "\t"
LINES TERMINATED BY '}' STARTING BY '{';
7. SingleStore Cloud DB에서 Kai for MongoDB API를 제공 ( MongoDB 가속)
- NoSQL로 유명한 MongoDB는 대용량 데이터 보관을 위한 비용 절감을 할 수 있고, MongoDB는 대량의 데이터 Aggregration과 조회가 용이한 장점을 가지고 있습니다.
- 다만 MongoDB의 느린 처리 속도와 Mongo만의 Json 기반 Query는 일반 개발자들도 이용하기 어렵다는 단점이 있습니다.
[ MongoDB 개선]
- SingleStoreDB에서 제공하는 MongoDB용 SingleStore Kai™ API를 이용하면 기존 MongoDB의 Query를 변경하거나 MongoDB용으로 작성된 애플리케이션 코드를 리팩터링할 필요 없이도 MongoDB 대비 분석 성능을 쉽게 극대화(10-100배) 할 수 있습니다.
또한 SingleStoreDB에서 제공하는 Data Migration 파이프라인(CDC기능 포함)을 이용하여 MongoDB에서 쉽게 전환이 가능합니다.
(https://www.singlestore.com/blog/introducing-singlestore-kai-for-mongodb/)

[MongoDB용 SingleStore Kai 의 주요 장점]
1) SingleStore 클라우드를 이용하여 MongoDB의 JSON 데이터 분석을 더 빠르게 수행(~ 100배)
2) MongoDB Proxy를 이용하여 Mongo API를 SQL로 변환하므로 코드 변경이나 데이터 변환 없이 사용 가능
(스키마 마이그레이션, 데이터의 ETL 변환, 어플리케이션 쿼리 변경 없이도 MongoDB의 변환이 용이함)
3) MongoDB API는 MongoDB API와 SQL API 를 모두 사용하여 개발이 가능 (NoSQL + SQL의 장점)
4) 추가 비용 없이 샤드 키만 정의하면 SingleStoreDB를 쉽게 확장할 수 있어 MongoDB와 같은 확장성을 제공
* MongoDB Client는 Mongo API Proxy를 이용하여 SQL로 변환하여 DB접근이 가능합니다.(Convert API to SQL)


8.LLM 함수 내장
chatGPT를이용하기 위해 필요한 LangChain 과 같은 함수와 내부 lamda-Index , Full-Text Search등의 기능을 제공하여 LLM기반 인공지능 구현이 용이 합니다.
9. SingleStore 활용 분야
- DBMS의 실시간 처리 성능 향상, 대량 트랜젝션 처리를 위한 차세대, MSA와 같은 데이터 아키텍처의 현대화 가 필요한 분야에 적합한 아키텍처를 제공합니다.

9. 다양한 분야 오픈소스 기술 통합과 관리 효율성 제공
다양한 오픈소스 기술을 통합하여 SigleStore로 대체가 가능합니다. 따라서 좀더 관리의 효율성과 아키텍처의 관리 부담을 줄일수 있습니다.

10. 주요 활용 사례
- Uber, Akamai 같은 해외 에서 클라우드 및 실시간 데이터 처리가 필요한 분야에서 활용 되고 있습니다.

[참고]
* 에이플랫폼 :
- http://www.a-platform.biz/singlestoreDB.html
* SilgleStore :
- https://www.singlestore.com/free/
* SingleStore Kai for MongoDB (Mongo 연계)
- https://docs.singlestore.com/managed-service/en/reference/singlestore-kai-for-mongodb.html
- https://cafe.naver.com/aplatformbiz/101
* SingelStore 기술 문서 (pc용):
- https://wiki.a-platform.biz/download
[Data 관련 참고 정리]
1. Bigdata - 데이터웨어 하우스 (DataWare House) 그리고 Data Lake
2.데이터 메시 (Data mesh) 원칙과 전략
3. 클라우드 네이티브 와 Event-Stream-Processing 플랫폼
4. (기술 트렌드)데이터 처리 환경의 변화와 미래
5. (기술)빅데이터 분석을 위한 고성능 DB기술 SingleStore