실시간 데이터 처리를 위한 Redpanda와 pinot 활용

실시간 데이터 처리를 위한 Redpanda와 pinot 활용
Redpanda는 Kafka와 같은 실시간 데이터 처리를 위한 데이터 스트리밍 기술 입니다. Pinot의 실시간 데이터 저장 기술을 활용하여 실시간 데이터 수집 저장과 조회가 가능한 OLAP 환경을 만들수가 있습니다.

Redpanda 설치와 pinot 연동
1. RedPanda 설치
panda-airlines다음 명령으로 호출되는 Docker 네트워크
docker network create panda-airlines
panda_airlines그런 다음 홈 디렉토리에 라는 폴더를 만듭니다 . 이후 단계를 위해 이 디렉터리를 Redpanda 컨테이너의 공유 볼륨으로 사용합니다.
_YOUR_HOME_DIRECTORY_다음 명령에서 자신의 홈 디렉터리로 바꾸고 실행합니다 .
docker run -d --pull=always --name=redpanda-1 --rm \
--network panda-airlines \
-v _YOUR_HOME_DIRECTORY_/panda_airlines:/tmp/panda_airlines \
-p 9092:9092 \
-p 9644:9644 \
docker.vectorized.io/vectorized/redpanda:latest \
redpanda start \
--advertise-kafka-addr redpanda-1 \
--overprovisioned \
--smp 1 \
--memory 2G \
--reserve-memory 1G \
--node-id 0 \
--check=false
리포지토리에서 최신 Redpanda 이미지를 가져오고 docker.vectorized.io노출된 포트 9092및 9644. 여기 에서는 9092Redpanda에 액세스하기 위해 포트를 사용합니다.
다음 명령을 실행하여 Redpanda 컨테이너의 유효성을 검사합니다.
docker ps
docker exec -it redpanda-1 \
BROKERS
=======
ID HOST PORT
0* redpanda-1 9092
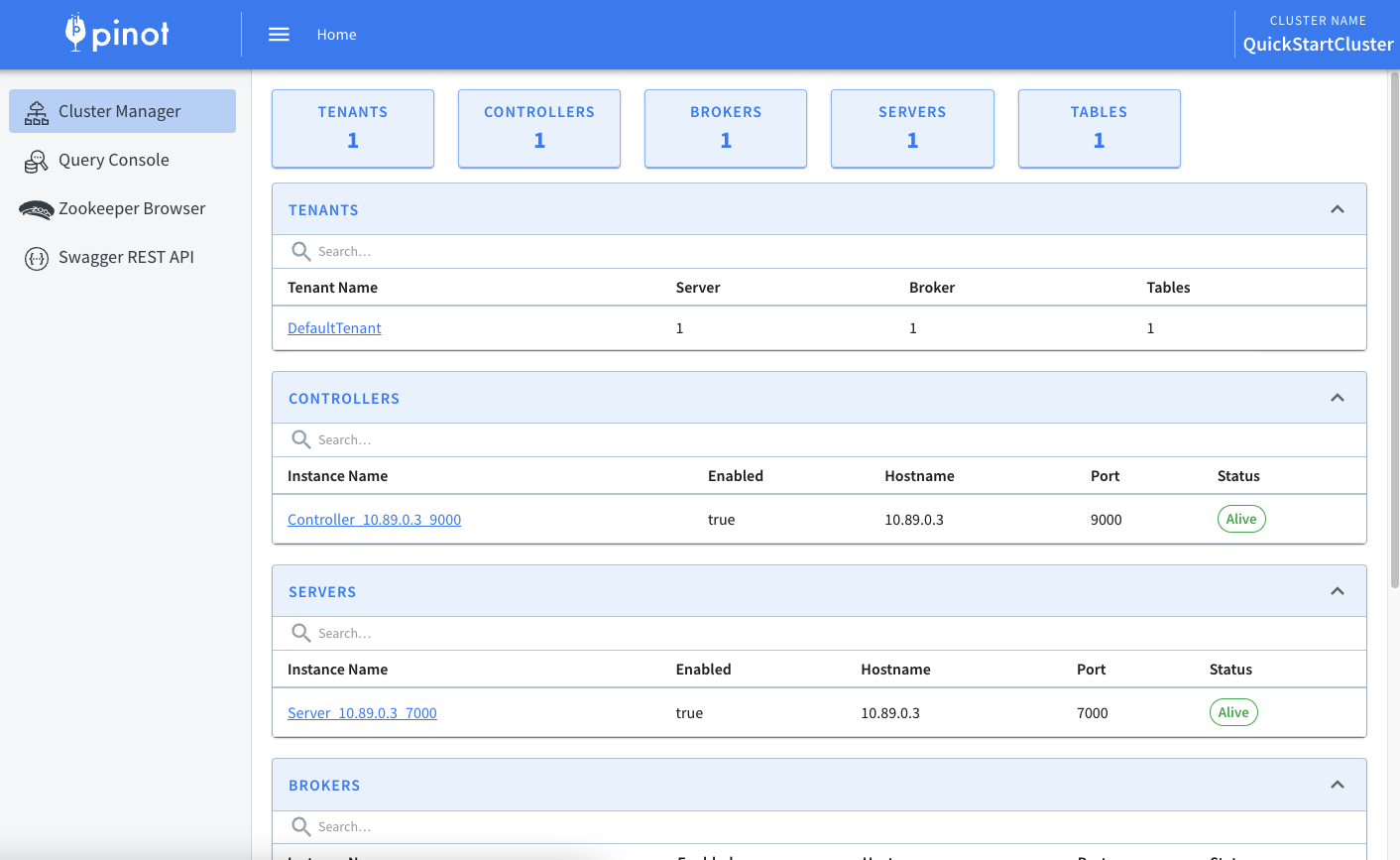
아래와 같이 브라우저에서 http://localhost:9000에서 Pinot 웹 인터페이스 화면을 볼 수 있습니다.
2. 데이터 스트리밍을 위해 Redpanda와 Pinot 통합
Redpanda에서 Pinot로의 데이터 흐름을 생성하려면 Redpanda에서 주제를 생성해야 합니다. 다음 명령을 사용하여 Redpanda 클러스터에서 flight라는 주제를 생성합니다.
docker exec -it redpanda-1 rpk topic create flights
docker exec -it redpanda-1 rpk cluster info
BROKERS
=======
ID HOST PORT
0* redpanda-1 9092
TOPICS
======
NAME PARTITIONS REPLICAS
flights 1 1
3. Pinnot 스키마생성
다음으로 Redpanda 연결 및 주제 정보로 구성할 Pinot에서 스키마와 테이블을 생성합니다.
아래와 같이 flights-table-realtime.json 파일로 스키마를 저장합니다.
{
"dimensionFieldSpecs": [
{ "dataType": "INT", "name": "ActualElapsedTime" },
{ "dataType": "INT", "name": "AirlineID" },
{"dataType": "STRING","name": "OriginCityName" },
{ "dataType": "STRING", "name": "OriginState" } ],
"dateTimeFieldSpecs": [
{ "name": "DaysSinceEpoch", "dataType": "INT", "format": "1:DAYS:EPOCH", "granularity": "1:DAYS" }
],
"schemaName": "flights"
}
파일에서 schemaName가 로 설정되어 있음에 유의 하십시오. flightsPinot에 테이블을 추가하는 동안 사용해야 하는 스키마 이름입니다. 다른 값은 테이블이 가져야 하는 필드 구조를 정의합니다.
dataType각 필드의 데이터 유형을 정의하고 name각 필드의 이름을 정의합니다. dateTimeFieldSpec 날짜/시간 필드는 Pinot에서 "format": "1:DAYS:EPOCH"와 같이 날짜/시간 필드를 구성할 수 있는도록 정의해야 합니다
4. Pinot 테이블 설정
pinot의 데이터가 저장될 tableName필드는 flights테이블 이름입니다.
flights-table-realtime.json이번에는 테이블에 대해 다음 콘텐츠를 사용하여 동일한 디렉터리에서 호출되는 다른 파일을 만듭니다 .
{
"tableName": "flights",
"tableType": "REALTIME",
"segmentsConfig": {
"timeColumnName": "DaysSinceEpoch",
"timeType": "DAYS",
"retentionTimeUnit": "DAYS",
"retentionTimeValue": "5",
"segmentPushType": "APPEND",
"segmentAssignmentStrategy": "BalanceNumSegmentAssignmentStrategy",
"schemaName": "flights",
"replication": "1",
"replicasPerPartition": "1"
},
"tenants": {},
"tableIndexConfig": {
"loadMode": "MMAP",
"streamConfigs": {
"streamType": "kafka",
"stream.kafka.consumer.type": "simple",
"stream.kafka.topic.name": TOPIC_NAME,
"stream.kafka.decoder.class.name": "org.apache.pinot.plugin.stream.kafka.KafkaJSONMessageDecoder",
"stream.kafka.consumer.factory.class.name": "org.apache.pinot.plugin.stream.kafka20.KafkaConsumerFactory",
"stream.kafka.broker.list": BROKER_ADDRESS,
"realtime.segment.flush.threshold.time": "3600000",
"realtime.segment.flush.threshold.rows": "50000",
"stream.kafka.consumer.prop.auto.offset.reset": "smallest"
}
},
"metadata": {
"customConfigs": {}
}
}
여기에서는 tableName필드는 flights테이블 이름이며 스키마와 같은 이름이지만 원하는 이름을 정의할 수 있습니다. 반드시 같은 이름을 사용해야 하는 것은 아닙니다.
Redpanda에서 생성한 주제를 나타내는 문자열 값으로 TOPIC_NAME설정 합니다. 또한 이 테이블 에 대한 Redpanda-Pinot 통신을 위해 를 flights변경해야 합니다. 이 구성을 사용하면 Redpanda 주제에서 Pinot 테이블로 데이터 수집이 가능합니다.BROKER_ADDRESSredpanda-1:9092
5. pinot 테이블에 데이터 스키마 적용
다음 명령을 실행하여 스키마와 테이블을 Pinot에 적용하십시오.
docker exec -it apachepinot-1 \
bin/pinot-admin.sh AddTable \
-schemaFile /tmp/panda_airlines/flights-schema.json \
-tableConfigFile /tmp/panda_airlines/flights-table-realtime.json \
-exec
이 명령에는 AddTable스키마 파일과 생성한 테이블 구성 파일이 필요한 Pinot의 명령이 포함되어 있습니다.
6 Redpanda를 통해 Pinot으로 데이터 보내기
이제 2014년에 속하는 Panda Airlines 비행 데이터가 포함된 JSON 파일을 다운로드해 보겠습니다. 비행 데이터를 다운로드하려면 이 링크 로 이동하여 다운로드를 클릭합니다. 파일 이름은 flights-data.json.
docker exec -it redpanda-1 /bin/sh -c \
'rpk topic produce flights < /tmp/panda_airlines/flights-data.json'
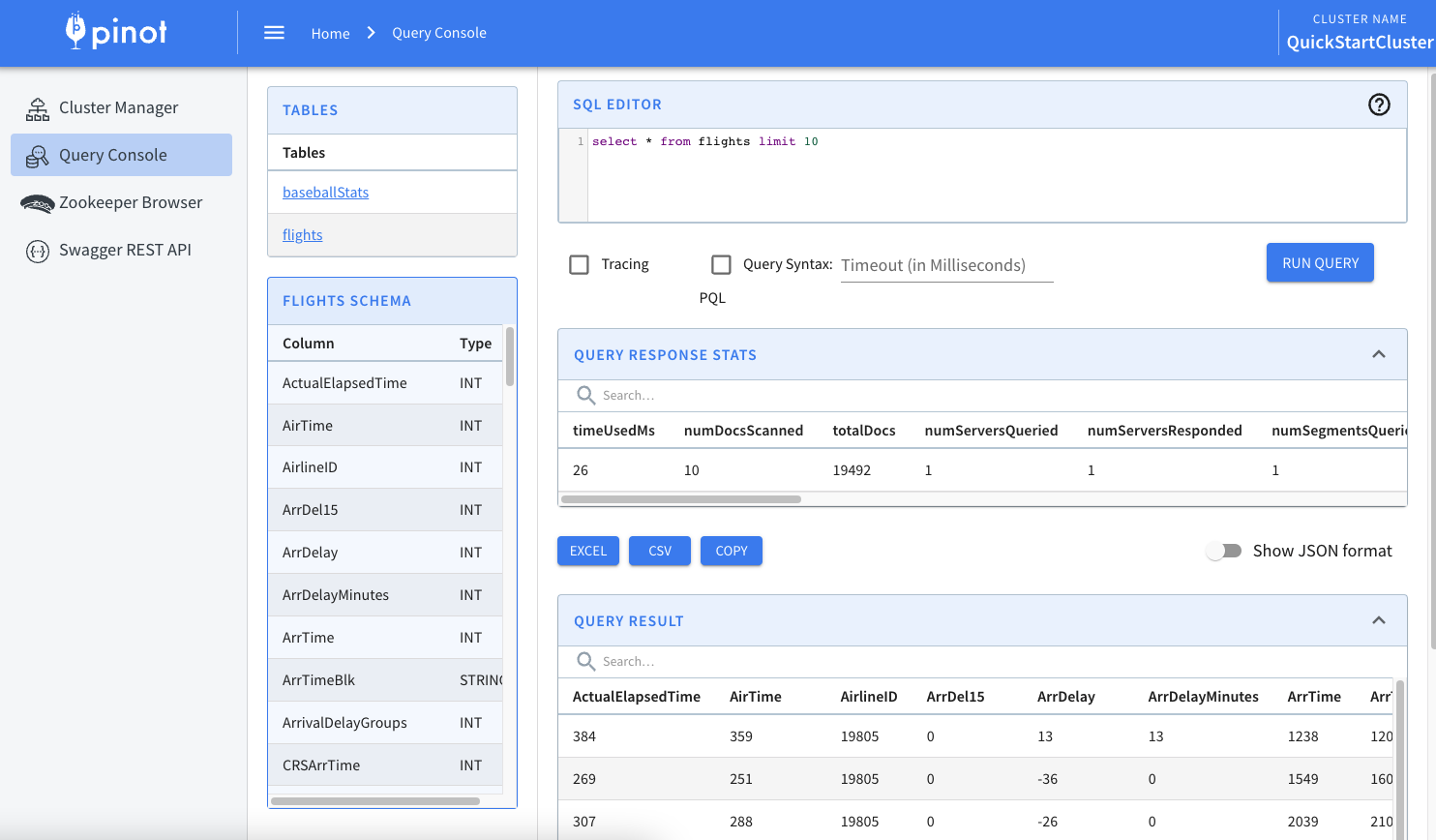
Redpanda 및 해당 CLI 기반 생산자를 사용하여 가져온 데이터에 속하는 쿼리 결과를 나열 하는 섹션뿐만 아니라 쿼리 SQL EDITOR가 있는 페이지 상단에 섹션 이 표시되어야 합니다 .select * from flights limit 10QUERY RESULTS
Panda Airlines에서 요구하는 비행 기록 수를 찾으려면 다음 차트의 키와 값을 사용하고 SQL 명령을 작성하십시오. 각 키는 flight 테이블의 필드를 나타냅니다.
| Table Field | Value |
| Dest | JFK |
| AirTime | > 300 |
| Month | 1 |
| Year | 2014 |
| OriginStateName | California |
SQL 명령은 다음과 같아야 합니다.
select count(*) from flights
where Dest='JFK'
and AirTime > 300
and OriginStateName='California'
and Month=1
and Year=2014
Redpanda와 해당 rpkCLI를 사용하면 모든 Kafka API 호환 스트리밍 플랫폼에서 데이터 수집을 위한 Pinot의 내장 기능을 통해 모든 데이터를 Pinot 테이블로 스트리밍할 수 있습니다. 이를 수행하는 방법을 알면 방대한 양의 데이터를 빠르고 효율적인 방식으로 통합, 스트리밍 및 분석할 수 있습니다.
[참조]
https://softwareengineeringdaily.com/2021/01/22/redpanda-kafka-alternative-with-alexander-gallego/
https://couplewith.tistory.com/entry/실시간분석을 위한 OLAP 저장소 Apache pinot
https://redpanda.com/blog/streaming-data-apache-pinot-kafka-connect-redpanda
https://redpanda.com/

Redpanda는 Kafka와 호환되도록 구축된 스트리밍 플랫폼으로 JVM이나 Zookeeper가 필요하지 않습니다. 두 가지 모두 Kafka를 필요 이상으로 사용하기 어렵게 만드는 종속성입니다.