(트렌드)클라우드 데이터 기술: Event-Stream-Processing 플랫폼
(트렌드)클라우드 데이터 기술: Event-Stream-Processing 플랫폼(NATS,KAFKA,Pulsar)
최근 몇 년 동안 사물인터넷(IoT) 기기를 중심으로 엄청난 발전이 있었습니다. IOT 기기 간 데이터를 실시간으로 처리하는 등 IT 산업에 많은 새로운 기술이 요구 되고 있습니다. 처리량을 높이기 용이하게 확장 가능하고, 대기 시간이 짧은 시스템에 대한 요구가 더욱 높아졌습니다.
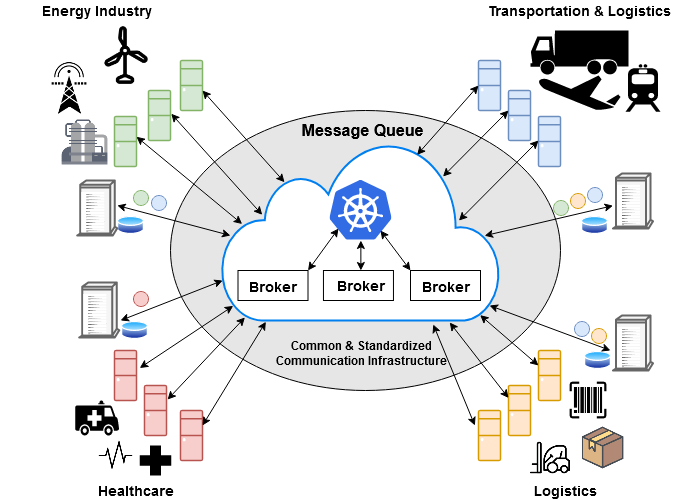
그리고 클라우드 네이티브 애플리케이션이 쿠버네티스 클러스터로 시스템 구축이 보편화 되면서 Micro Service 형태로 다양한 서비스 간의 메시지 통신이 발달하고 있습니다. 메시지 대기열 시스템(Message Queue)과 스테이트풀(Stateful) 시스템으로 이용하는 Kafka, NATS Streaming(STAN) 및 RabbitMQ 등의 메시지 시스템에 대한 정리를 해보았습니다.
0. Streaming Data 처리
1. Event-Stream-Processing 플랫폼 이 필요한 이유
2. 이벤트 프로세싱 플랫폼의 구성과 특징
3. 이벤트 프로세싱 플랫폼의 종류 와 특징
0. 스트리밍 데이터 처리
일반적으로 스트리밍 데이터는 수많은 데이터 소스에서 지속적으로 들어오는 데이터의 무한한 흐름을 말합니다. 한 가지 예로는 습도, 기압 및 공기 품질과 같은 다양한 IOT 센서들로 구성된 스마트 센서 네트워크를 예로 들수 있습니다.
이 센서들의 실시간으로 측정값을 계속해서 처리 장치로 보내 제조 라인의 환경을 모니터링하고 있습니다. 스트리밍 데이터의 시간 순서는 시간 경과에 따른 데이터의 변화와 추세를 나타내는 것이 매우 중요합니다. 따라서 스트리밍 데이터는 실시간 데이터 분석을 제공하고 신속한 대응이 가능하도록 연속적이고 순차적으로 새로운 데이터 레코드가 도착할 때 수신 및 처리되어야 합니다. 스트리밍 데이터 응용 프로그램의 몇 가지 추가 예는 네트워크 트래픽 모니터링, 금융 거래 층, 웹 페이지 모니터링에서의 고객 상호 작용하는 방식으로 활용 되고 있습니다.
1. Event-Stream-Processing 플랫폼 이 필요한 이유
분산 시스템 또는 마이크로서비스 애플리케이션을 구축할 때 주요 관심사 중 하나는 시스템 간 및 서비스 간 데이터 교환을 처리하는 방식입니다. 최근 이벤트 기반의 플랫폼 (이벤트 드리븐 : Event-Driven) 개발 방법은 다양한 서비스 도메인별 시스템을 분리하여, 서로 독립적인 플랫폼으로 구성하는 Micro-Service Architect를 지향하고 있습니다.
독립적인 시스템 구성의 느슨한 결합으로 구현된 마이크로 서비스는 다른 언어로 구현되거나 특정 작업에 적절한 다른 기술을 사용하기 용이합니다. 물론 시스템의 다양성으로 개발 환경이 복잡해 지고 유지보수도 어려워 지는 단점도 있지만 서비스 환경을 빠르고 유연하게 비즈니스를 확장하기 위해서 채택되는 방식으로 이해 할 수 있습니다.
이러한 환경에서 Event-Stream-Processing을 통해서 서비스 간의 대량의 데이터를 실시간 교환 하는 의미도 있지만 이기종 또는 다른 서비스간의 데이터 송수신을 위한 표준화된 데이터 교환도 주요하다. 또한 서비스간의 대량의 데이터를 안전하고 신뢰성 있게 전달 하는 기술로 Event-Stream-Processing 플랫폼이 필요하다고 할 수 있다.
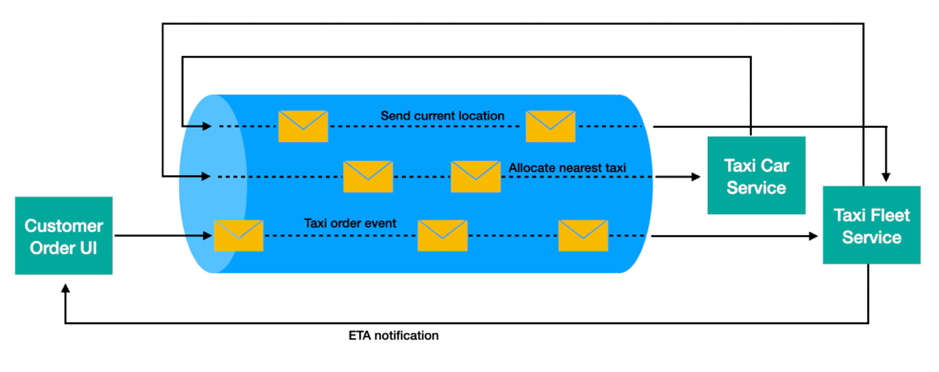
고객이 택시를 호출하고 주문하는 화면, 택시 서비스에서 주문과 가까운 거리의 택시를 호출하고, 근처의 택시를 할당 하는 차량 서비스 및 개인에 대한 데이터를 수집하는 택시 서비스와 같은 시나리오처럼 마이크로 서비스는 서로 다른 서비스간의 유기적인 연결이 되어 있다. 이와 같이 다양한 마이크로서비스끼리 연결하는 다이어그램 중앙의 이벤트 실린더는 시스템의 이벤트 기반 메시징 백본을 나타냅니다. (이벤트 메시징 백본은 주로 Apache Kafka와 같은 것으로 구현할 수 있다.)
2. 이벤트 프로세싱 플랫폼의 구성과 특징
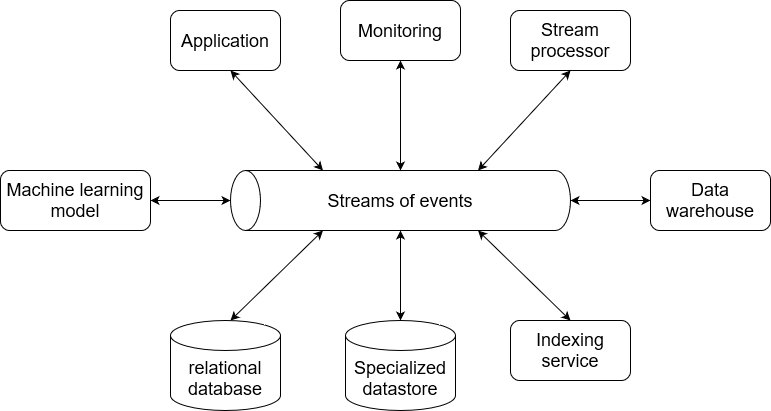
이벤트 스트림의 구성은 이벤트 스트림을 처리하는 데이터 백본을 인프라의 중앙에 배치하는 것이 이상적입니다. 이러한 스트림은 지속적으로 처리 및 변환되는 다양한 형태의 데이터을 처리하고, 시스템 간의 접근을 비정규화 하여 처리 할 수 있습니다.
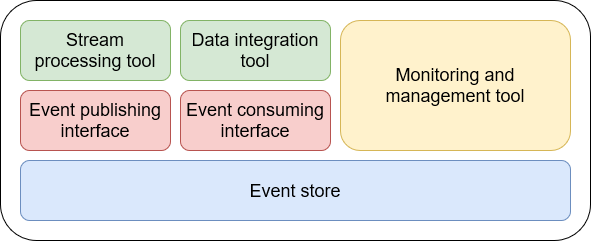
2.1 이벤트 플랫폼의 구성 요소
| 이벤트 저장소 | 지속적으로 유입되는 이벤트를 저장하고 처리하는 계층 |
| 이벤트 게시/소비 | 이벤트 유입과 소비를 위한 Async 방식의 수단을 제공하여 데이터 스트림 전송 |
| 스트림 처리 | 이벤트 스트림의 신속한 처리를 위한 프로세스 기술 |
| 데이터 통합 | 다양한 데이터의 입출력을 처리 하기 위한 통합된 데이터 통합 기술 |
| 모니터링 및 관리 | 대용량의 플랫폼을 데이터 흐름을 관리하고 모니터링 하는 도구 |
3. 이벤트 프로세싱 플랫폼의 종류 와 특징
- KAFKA, Pulsar, NATS Streaming

3.1 KAFKA 카프카
Kafka는 호출되는 데이터 스트림 또는 레코드 스트림을 전송, 저장, 처리를 용이하게 하는 애플리케이션을 구축하는 기술 입니다. Kafka는 하나 이상의 서버에 걸쳐 클러스터로 구축되며 Kafka 클라이언트와 다른 데이터 시스템 간의 레코드 스트림을 저장하고 전송하는 분산 메시지 브로커 방식의 역할을 합니다
Kafka 클러스터에 게시된 레코드는 여러개의 topic 으로 나누어 처리를 할 수 있습니다. Kafka 클러스터는 로그의 각 파티션 내에서 레코드가 토픽에 기록될 때 레코드의 순서를 보장하기 위해 분할된 로그 형식으로 각 토픽을 관리 합니다.
각 레코드는 파티션 끝에 추가되는 새 레코드는 도착하는 순서대로 각 파티션에 저장됩니다. 각 레코드는 오프셋 이라는 특정 번호로 레이블이 지정됩니다. 동일한 키를 가진 레코드가 항상 동일한 파티션에 게시되므로 시간 순서가 유지됩니다.
Kafka의 구성 요소와 특징
topic, partiton : 메세지는 topic으로 분류되고, topic은 여러개의 파티션으로 나누어 저장 됩니다. 데이터는 한 파티션 내에서 순차적으로 append됩니다. 메세지의 상대적인 위치를 나타내는 offset을 통해 메시지의 순서대로 처리할 수 있습니다. 하나의 토픽을 여러개의 파티션을 나누면 동시에 append되는 수천개의 메지시를 병렬로 처리가 가능해 집니다.
(주의사항) 한 번 늘린 파티션은 절대로 줄일 수 없으므로 파티션을 늘리는 것은 신중히 고려 해야 합니다. 또한 각 파티션에 저장되는 메세지는 Round-robin방식으로 저장됩니다. 따라서 토픽마다 메시지가 저장되는 순서를 보장 하지 못하므로 시간적인 순서를 중요시 하는 금융 시스템에서 활용하는데는 제한이 있습니다.
Producer, Consumer :
Producer는 메세지를 만들고 Topic에 메세지를 보냅니다. 여러개의 토픽에 여러개의 파티션을 나누고, 특정 메세지들을 분류해서 특정 파티션에 저장하려면 key 값을 통해서 분류해서 넣을 수 있습니다.
Consumer는 소비자로써 메세지를 소비하는 주체입니다. 해당 topic을 구독하여 토픽의 데이터를 읽을수 있습니다. topic의 각 파티션에 존재하는 offset의 위치를 이용하여 마지막 읽은 offset위치를 기억합니다. 장애 처리 후 마지막 읽었던 위치에서 Consumer가 다시 읽어들일 수 있습니다.
consumer group : Consumer 그룹은 consumer들의 묶음 단위 입니다. topic의 파티션은 하나 이상의 consumer group과 1:n 으로 연결 가능합니다. 파티션의 수는 > 컨슈머그룹 내의 컨슈머 수보다 많아야 합니다. 만약 파이션수 보다 컨수머를 많이 작동하면 남는 컨슈머는 작동을 하지 않고 예비로 남겨집니다.
(주의사항) 각 Consumer group 단위 별로 offset을 관리하므로 서로 다른 컨슈머 그룹끼리 영향을 주지 않고 메시지를 복제하여 독립적으로 처리가 가능합니다.
bin/kafka-consumer-groups --bootstrap-server host:9092 --list
testgroup
foogroup
bin/kafka-consumer-groups --bootstrap-server host:9092 --describe --group foogroup
broker, zookeepr : zookeeper는 이러한 분산 메세지 큐의 정보를 관리해 주는 역할을 합니다. broker.id=1..n으로써 동일한 노드내에서 여러개의 broker서버를 구동 할 수 있습니다.
replication: Kafka의 분산 저장소내에 메지지의 복제를 통해 노드의 장애시 메시지의 유실이 없도록 클러스터간의 데이터를 복제 해 둘수 있습니다. –replication-factor 1 은 복제를 하지 않는 것이고 –replication-factor 2은 클러스터 내 서로 다른 노드에 2개의 데이터를 중복 복제하여 보관 하는 것입니다. 만약 노드가 3개로 구성 되었다면 노드 중의 하나가 중지되더라도 다른 노드에서 복제 데이터를 가지고 있으므로 서비스의 무중단 상태로 처리가 가능해 집니다.
(주의사항) Replication은 topic을 복제하는 것이 아니라 Topic내의 각 Partition을 복제 하는 것입니다.
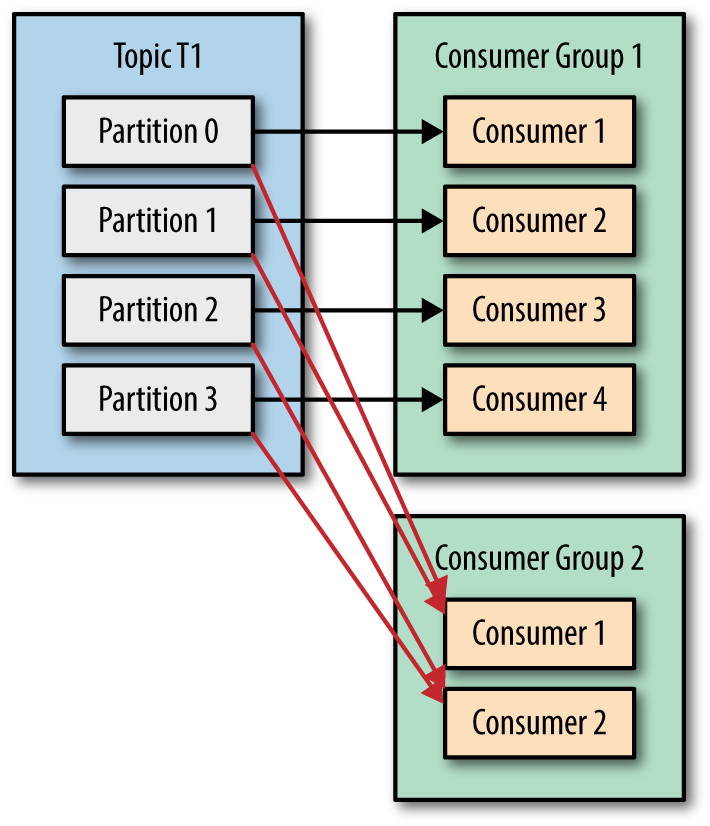
Kafka Topic을 작은 파티션으로 나누는 이점
- 확장성 : 토픽의 주제 단위로 여러 서버에 분산하여 저장하므로 더 큰 크기의 스토리지 용량을 저장 할 수 있습니다.
- 병렬성 : 토픽은 각 소비자가 토픽의 특정 파티션을 고유하게 처리하는 동시에 다른 소비자에 의해 처리될 수 있습니다.
- 내결함성 : 두 가지 유형의 파티션, 리더 및 팔로워 가 있습니다. 클라이언트는 리더 파티션에만 읽고 쓸 수 있지만 팔로워 파티션은 리더의 복제이며 클러스터의 다른 서버 노드에 분산되어 있으며 서버가 고장난 경우 리더 파티션을 교체하는 데 사용할 수 있습니다.
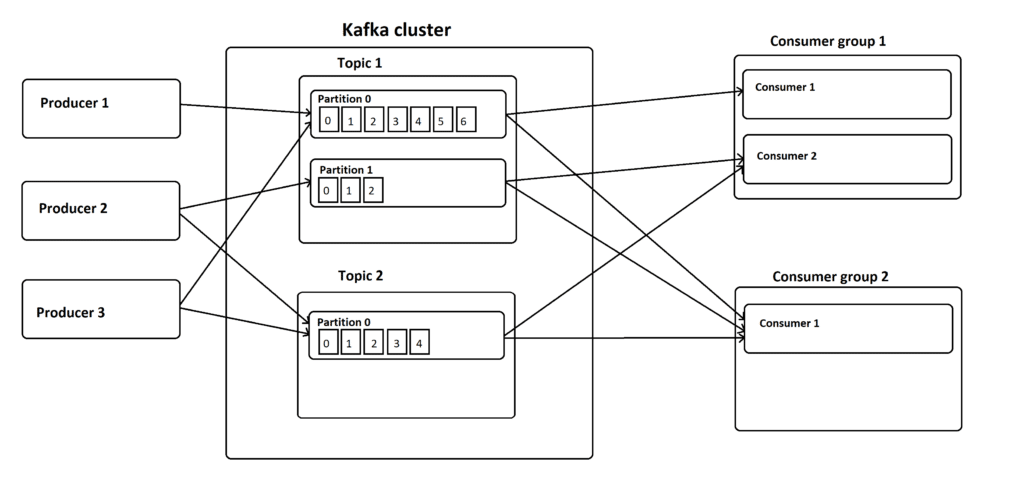
모든 기록은 구성된 기간 동안 Kafka 클러스터에 보관됩니다. 이 보존 기간을 무한으로 설정하여 기록을 영구적으로 저장하는 것도 가능합니다. 이 기간 동안 소비자는 오프셋 번호를 사용하여 할당된 파티션의 모든 레코드를 읽을 수 있습니다.

3.2 Pulsa 펄사
Apache Pulsar는 원래 Yahoo!에서 만든 분산 메시징 및 스트리밍 플랫폼입니다.
Pulsar 의 구성 요소와 특징
- Pulsar 브로커: Pulsar 브로커는 REST API를 통해 클라이언트에서 들어오는 메시지를 처리하고 로드밸런싱하여 메지시를 소비자에게 발송하는 역할을 합니다. Kafka와 달리 Pulsar 브로커는 상태를 저장하지 않습니다. 클라이언트로부터 요청을 받을 때마다 클러스터의 스토리지 계층을 호출하여 필요한 데이터와 정보를 검색합니다.
- BookKeeper 저장 계층: Pulsar의 저장 계층은 하나 이상으로 구성된 분산 로그 원장입니다. 메시지나 이벤트를 유지하는 오픈 소스 스토리지 서비스입니다.
- Zookeeper: Pulsar는 Zookeeper를 사용하여 클러스터에서 브로커와 BookKeeper 노드(일반적으로 Bookies라고 함)의 모든 메타데이터를 관리합니다.
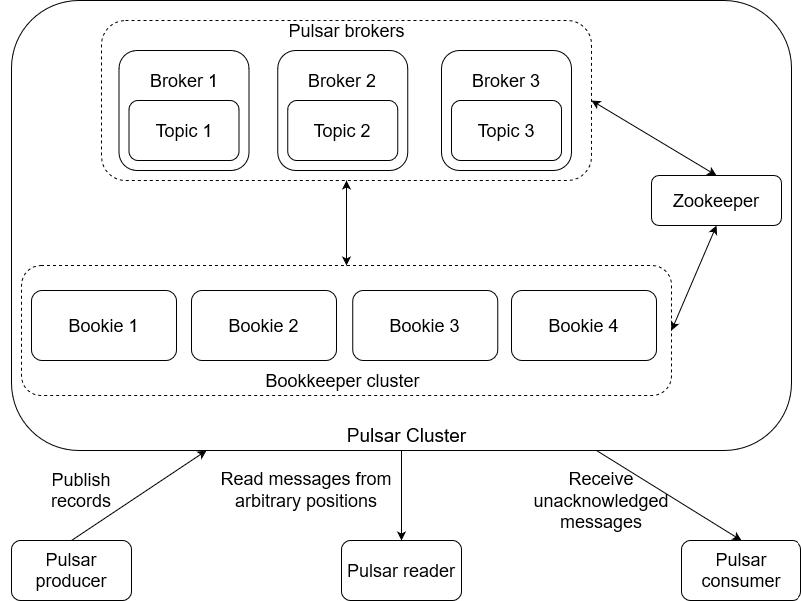
Pulsar에 게시된 메시지는 BookKeeper 원장 위에 있는 Pulsar의 논리적 스토리지 추상화인 다양한 주제로 구성됩니다. Pulsar 주제는 논리적으로 여러 파티션으로 분할될 수 있습니다. Topic 내부 파티셔닝을 통해 여러 클라이언트 인스턴스가 이벤트 스트리밍 사용시 확장성을 위해 Pulsar 주제를 공동으로 사용할 수 있습니다.

3.3 NATS Streaming 나츠 스트리밍
NATS와 NATS 스트리밍은 모두 Go언어로 작성되어 있습니다. NATS 스트리밍은 성능이 매우 뛰어나고 가볍지만 일부 기능과 성숙도 측면에서 Kafka와 같은 분산 스트리밍 시스템만큼 강력하지 않다는 의견입니다.
차세대 NATS NATS 2.0은 NATS JetStream으로 알려져 있습니다. 따라서 분산 시스템, IoT 및 Edge를 구축하기 위해 스트리밍 시스템을 사용하려면 NATS 스트리밍보다 NATS JetStream을 사용하는 것이 좋습니다.
NATS Streaming은 NATS 메시징 시스템 위에 구축된 오픈 소스 Event-Streaming-Processing(ESP) 플랫폼입니다. 현현재 NATS Streaming은 더 이상 활발히 개발되지 않고 JetStream 이라는 다른 새 프로젝트로 대체될 예정 이지만 새 프로젝트도
NATS 위에 구축되었으며 NATS Streaming과 유사한 개념을 가지고 있습니다.
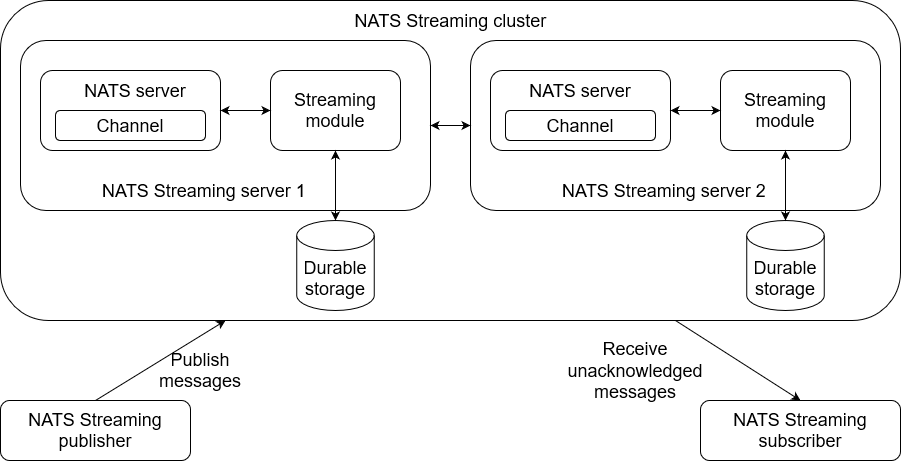
NATS 스트리밍 클러스터는 일반적으로 여러 서버 인스턴스로 그룹화 되어 있습니다.
NATS 스트리밍 서버는 메시지 전달을 담당하는 일반 NATS 서버와 지속성 기능을 담당하는 스트리밍 모듈로 구성됩니다.
메시지를 NATS 스트리밍 publisher 로 전송하면 NATS Streaming 서버로 전달 됩니다. 그 다음 수신 스트리밍 모듈에서 데이터를 수신하고 저장소에 유지합니다.
클라이언트 스트리밍 Subscriber 가 메시지를 사용하려고 할 때 스트리밍 모듈은 지속성 계층에서 메시지를 검색하고 NATS 서버를 통해 클라이언트로 보냅니다.
(유의사항) 클라이언트와 스트리밍 모듈 사이에는 직접적인 연결이 없습니다. 따라서 메시지가 게시되고 NATS 서버와 스트리밍 모듈 간의 연결이 중단되면, NATS 서버의 메시징 계층이 비영구적이므로 메시지가 손실됩니다.
지속성 계층으로 스트리밍 서버에 다양한 Durable Storage 시스템을 유연하게 연결할 수 있습니다. 현재 NATS 스트리밍은 두 가지 유형의 지속성 계층을 지원합니다. 즉, 메시지(또는 이벤트)는 서버 인스턴스의 파일 시스템에서 직접 지속되거나 관계형 데이터베이스에 저장될 수 있습니다.
NATS 스트리밍의 메시지는 다른 채널로 구성됩니다. NATS 스트리밍은 채널에서 메시지를 게시하고 구독하기 위한 클라이언트 API를 제공합니다.
Kafka 및 Pulsar와 달리 NATS 채널은 더 이상 분할할 수 없는 최소 소비 단위입니다. 클라이언트가 NATS 채널에 가입하면 서버는 각 가입자의 소비 상태를 유지하고 가입자는 각 메시지를 소비한 후 서버에서 승인해야 합니다. 그렇지 않으면 서버는 승인되지 않은 메시지를 클라이언트에 계속 다시 푸시하게 됩니다.
NATS의 특징
-
메시지 프로토콜 - NATS 스트리밍은 Google 프로토콜 버퍼 를 사용하여 향상된 메시지 형식을 구현합니다 . 메시지는 NATS 내부에서 바이너리 메시지 페이로드로 전송되므로 기본 NATS 프로토콜을 변경할 필요가 없습니다.
-
메시지/이벤트 지속성 - NATS 스트리밍은 메모리 내에서 플랫 파일 또는 데이터베이스와 같이 구성 가능한 메시지 지속성을 제공합니다. 스토리지 하위 시스템을 사용자가 정의 구현 할 수 있도록 공용 인터페이스를 사용합니다.
-
최소 한 번 배달 - NATS 스트리밍은 게시자와 서버(게시 작업용) 및 구독자와 서버(메시지 배달 확인용) 간에 메시지 승인을 제공합니다. 메시지는 메모리 또는 보조 저장소(또는 기타 외부 저장소)의 서버에 의해 유지되며 필요에 따라 구독 클라이언트에 다시 전달됩니다.
-
게시자 속도 제한 (MaxPubAcksInFlight)- NATS 스트리밍은 게시자가 주어진 시간에 진행 중인 미확인 메시지 수를 효과적으로 제한하는 연결 옵션을 제공합니다. 이 최대값에 도달하면 승인되지 않은 메시지 수가 지정된 제한 아래로 떨어질 때까지 추가 비동기 게시 호출이 차단됩니다.
-
구독자당 비율 일치/제한(MaxInFlightNATS) - 스트리밍이 주어진 구독에 대해 허용할 미해결 확인(전달되었지만 확인되지 않은 메시지)의 최대 수를 지정하는 옵션을 지정할 수 있습니다. 이 제한에 도달하면 NATS 스트리밍은 승인되지 않은 메시지 수가 지정된 제한 아래로 떨어질 때까지 이 구독에 대한 메시지 전달을 일시 중단합니다.
-
제목별 메시지 재생 기록 - 새 구독은 구독된 제목의 채널에 대해 저장된 메시지 스트림의 시작 위치를 지정할 수 있습니다. 이 옵션을 사용하면 다음 위치에서 메시지 배달을 시작할 수 있습니다.
-
이 주제에 대해 저장된 가장 오래된 메시지
-
현재 구독이 시작되기 전에 이 주제에 대해 가장 최근에 저장된 메시지입니다. 이것은 일반적으로 "마지막 값" 또는 "초기 값" 캐싱으로 생각됩니다.
-
나노초 단위의 특정 날짜/시간
-
현재 서버 날짜/시간의 과거 오프셋(예: 지난 30초).
-
특정 메시지 시퀀스 번호
-
-
영구 구독 - 구독은 클라이언트가 다시 시작된 후에도 지속되는 "영구 이름"을 지정할 수도 있습니다. 지속 구독은 서버가 클라이언트와 지속 이름에 대해 마지막으로 확인된 메시지 시퀀스 번호를 추적하도록 합니다. 클라이언트가 다시 시작/재구독하고 동일한 클라이언트 ID와 지속성 이름을 사용하면 서버는 이 지속성 구독에 대한 가장 먼저 확인되지 않은 메시지부터 배달을 재개합니다.
[Data 관련 참고 정리]
1. Bigdata - 데이터웨어 하우스 (DataWare House) 그리고 Data Lake
2.데이터 메시 (Data mesh) 원칙과 전략
3. 클라우드 네이티브 와 Event-Stream-Processing 플랫폼
4. (기술 트렌드)데이터 처리 환경의 변화와 미래
5. (기술)빅데이터 분석을 위한 고성능 DB기술 SingleStore
[참고]
1. (MSA) 마이크로 서비스간의 빠른 메시징 처리를 위한 NATS
(MSA) 마이크로 서비스간의 빠른 메시징 처리를 위한 NATS
(MSA) 마이크로 서비스간의 빠른 메시징 처리를 위한 NATS NATS를 사용한 경량의 클라우드 네이티브 메시징 #NATS #MSA #마이크로서비스 #고속메시징전송 NATS is a simple, secure and performant commun..
couplewith.tistory.com
https://docs.nats.io/legacy/stan/intro
STAN Concepts - NATS Docs
Durable subscriptions - Subscriptions may also specify a "durable name" which will survive client restarts. Durable subscriptions cause the server to track the last acknowledged message sequence number for a client and durable name. When the client restart
docs.nats.io
https://developer.ibm.com/articles/advantages-of-an-event-driven-architecture/
https://dzone.com/articles/benchmarking-nats-streaming-and-apache-kafka
Benchmarking NATS Streaming and Apache Kafka - DZone Performance
dzone.com
Building Distributed Event Streaming Systems In Go With NATS JetStream
In this post, I will give a brief introduction to NATS JetStream as a distributed event streaming system, which comes from the NATS…
shijuvar.medium.com
Apache Kafka
Apache Kafka: A Distributed Streaming Platform.
kafka.apache.org
https://www.novatec-gmbh.de/en/blog/kafka-101-series-part-1-introduction-to-kafka/
Kafka 101 Series - Part 1: Introduction to Kafka
Are you new to Apache Kafka and stream processing? Wondering why they are so popular and beloved? This blog series Kafka 101 is a good entry point for you.
www.novatec-gmbh.de
https://pulsar.apache.org/docs/en/concepts-architecture-overview/
Apache Pulsar
pulsar.apache.org